Observability
llm.port 帮助你快速看清 AI 系统每天的运行状态。
你可以直接回答这些问题:
- 请求是否稳定、是否够快?
- 哪些模型使用最多?
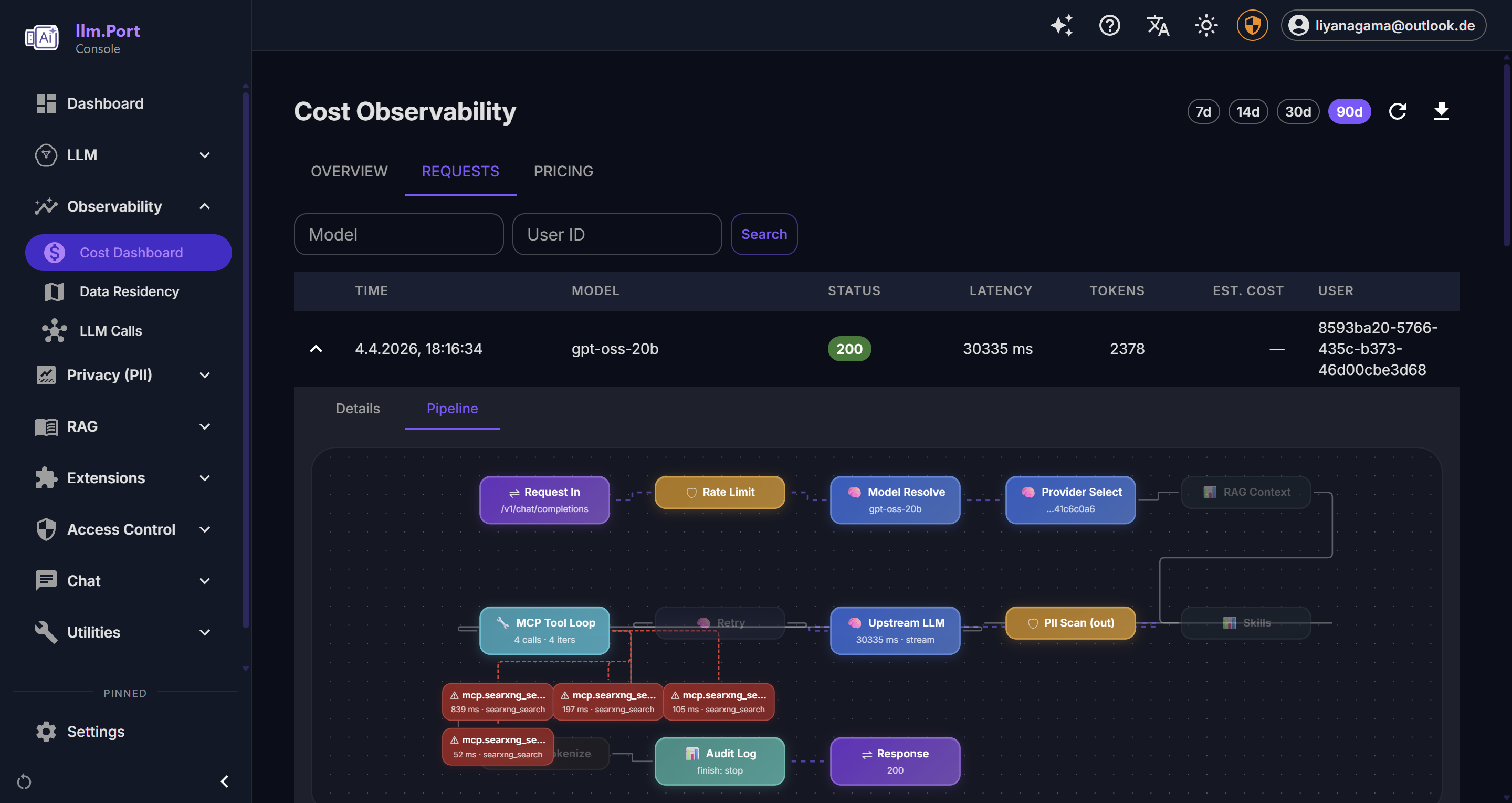
- 成本主要增长在哪里?
- 谁在什么时间做了什么变更?
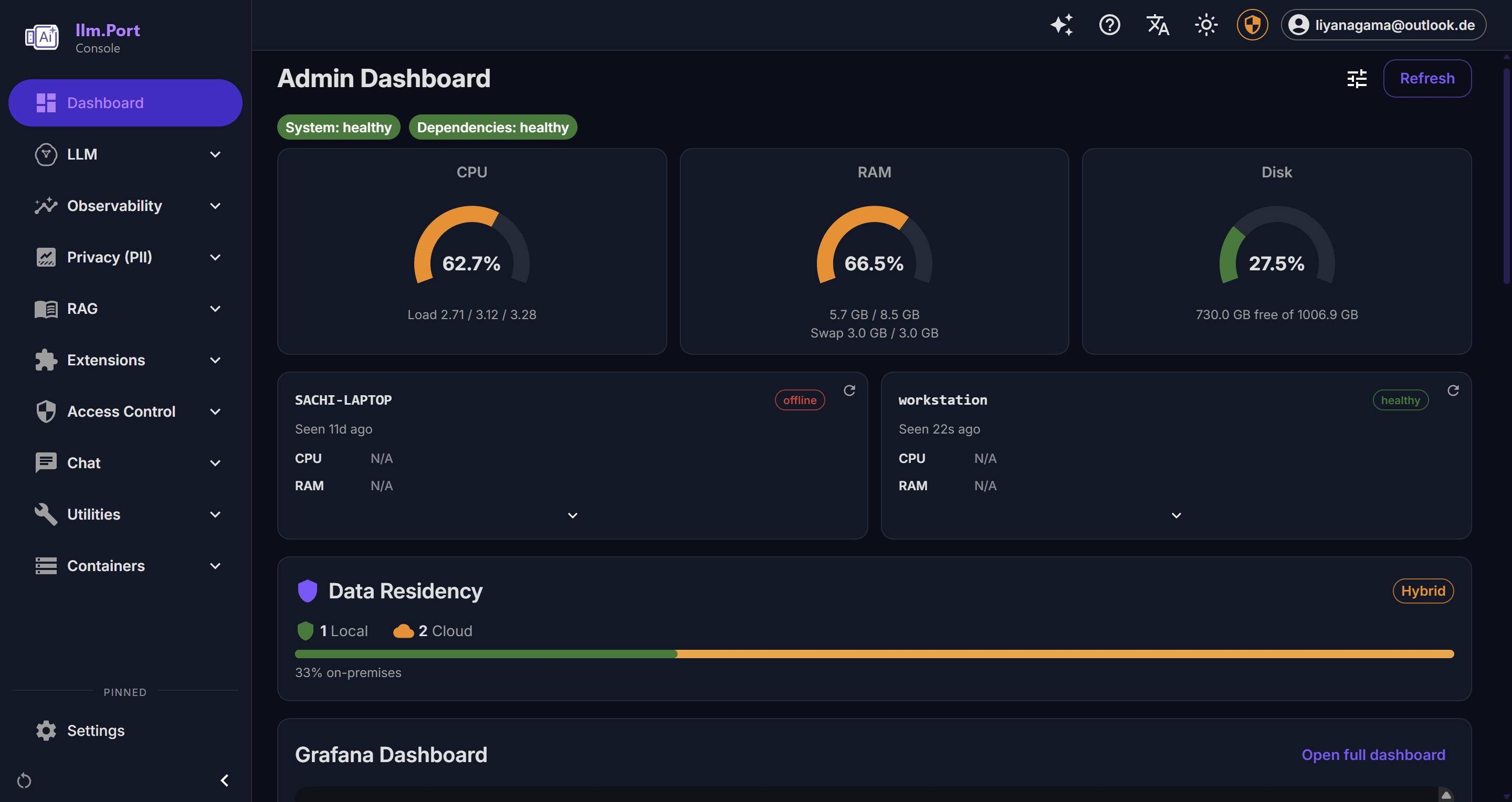
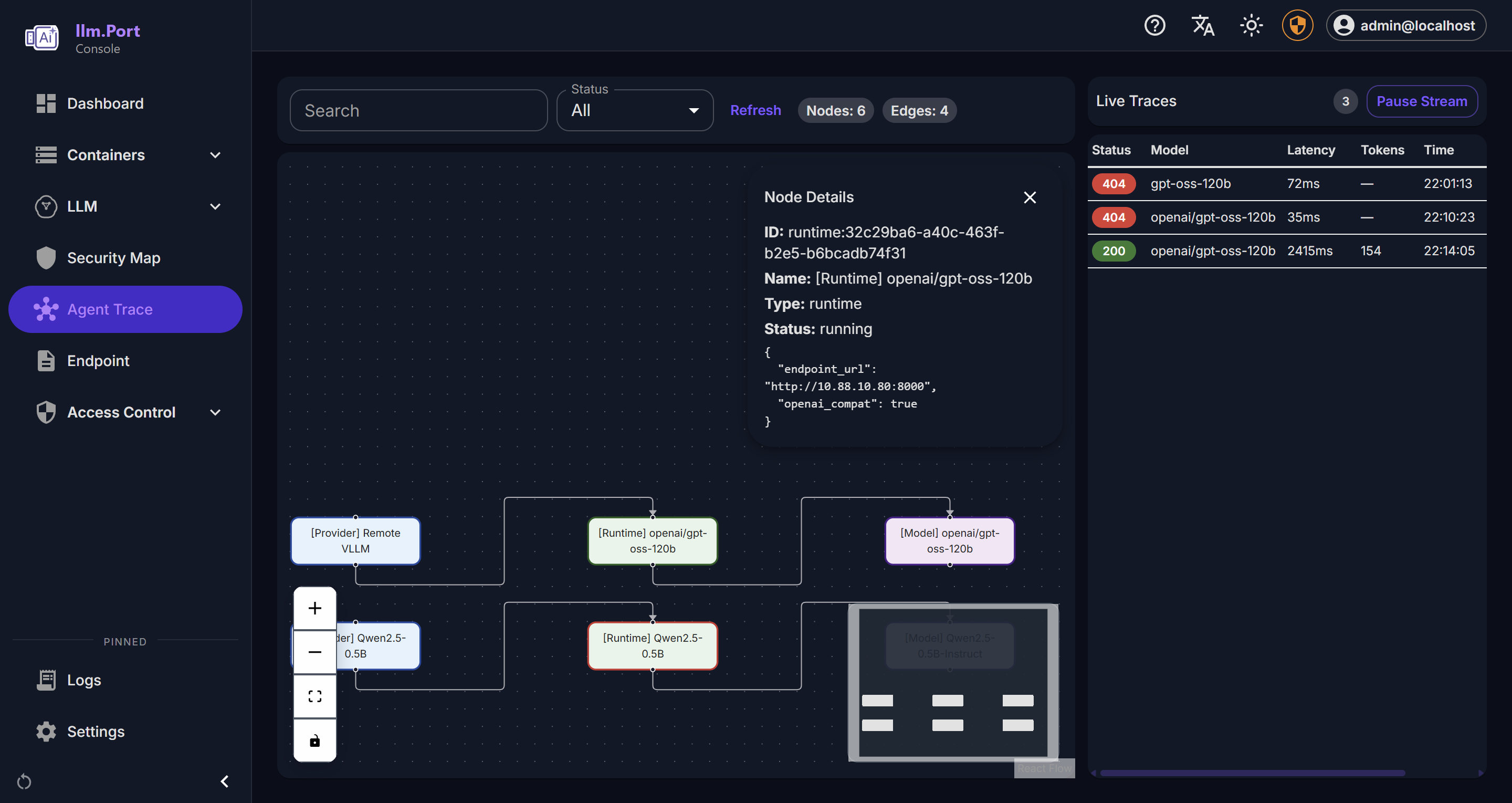
What you can observe
- Request activity and outcome trends
- Latency and throughput indicators
- System health and service behavior
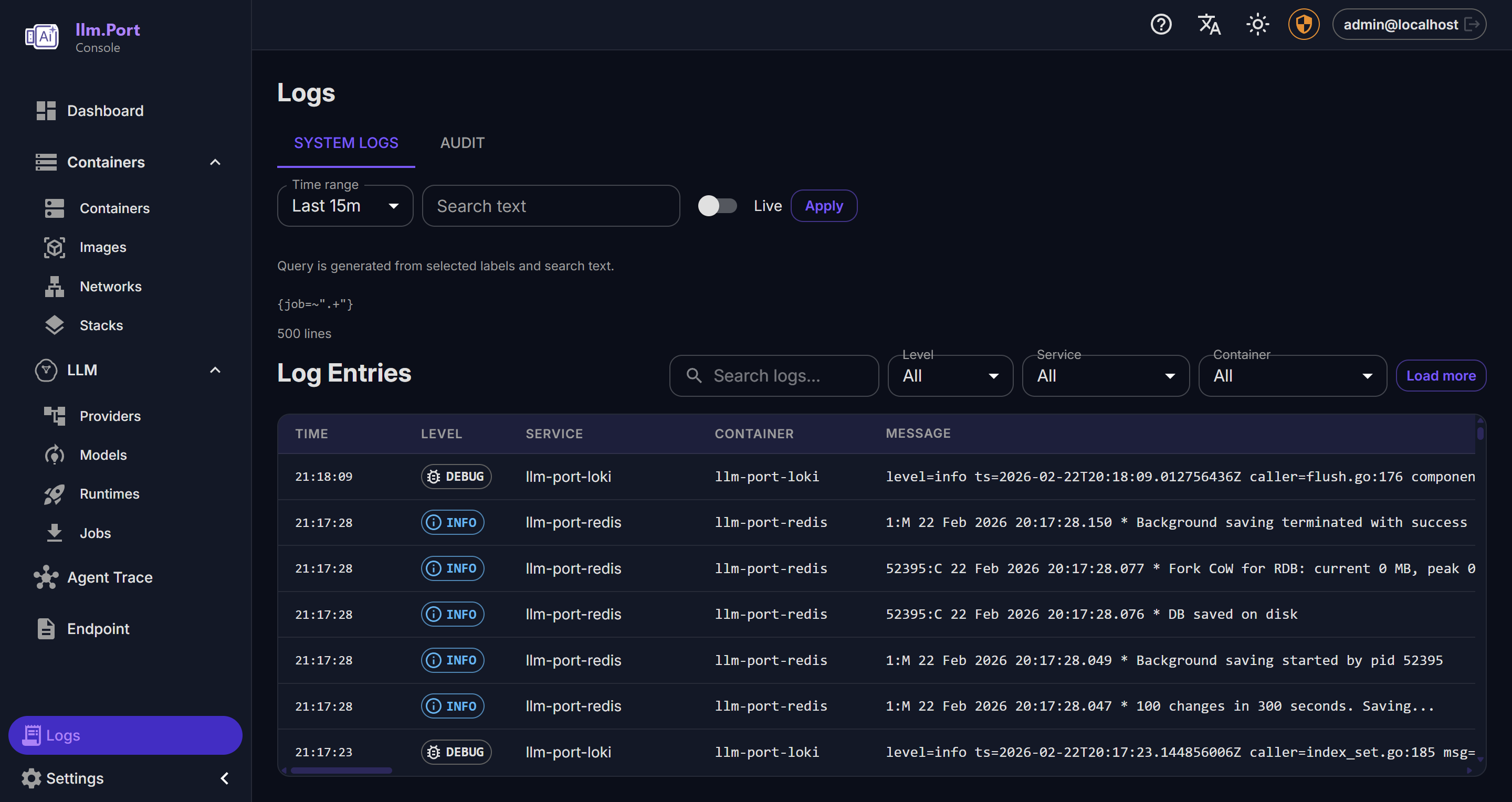
- Administrative action trails
Why this matters
- Faster incident detection and troubleshooting
- Better governance and compliance reporting
- Data for capacity planning and optimization
对多数团队来说,这会成为 AI 运维的统一事实来源。
Recommended operating practice
- Define alert thresholds for key service indicators
- Review usage and access trends regularly
- Keep retention policies aligned with compliance requirements
在 Requests 视图中,通常可以最快定位用户反馈的问题。
Public docs focus on observable outcomes and operating guidance, not internal telemetry plumbing.
Screenshots