llm.Port
Self-hosted all-in-one LLM platform
路由、保护和观测本地 LLM 运行时与远程提供商之间的流量 ── 为团队提供端到端管理 LLM 服务的统一平台。
# Install the CLI
$ pip install llmport-cli
# Check prerequisites & deploy
$ llmport doctor
$ llmport deploy
# Enable optional modules
$ llmport module enable pii
$ llmport module enable rag支持 English、Deutsch、Español、中文
工作原理
API 网关
兼容 OpenAI 的 /v1/* 端点。路由到 vLLM、llama.cpp、Ollama、TGI 及远程提供商(OpenAI、Azure 等)。SSE 流式传输、基于别名的模型解析、重试和速率限制。
PII 层
Microsoft Presidio 集成,用于实时检测和脱敏。租户级策略,可配置实体类型和故障安全模式。
GPU 编排
自动检测 NVIDIA (CUDA)、AMD (ROCm) 和 Intel GPU。使用正确的镜像(CUDA / ROCm / Legacy)启动 vLLM 容器。HuggingFace 缓存挂载实现快速模型加载。
存储
PostgreSQL + pgvector 用于向量搜索(RAG)。Redis 用于速率限制、会话缓存和分布式租约。MinIO 用于兼容 S3 的文档存储。
可观测性
Langfuse 用于 LLM 追踪(含隐私模式)。Grafana + Loki + Alloy 用于集中式日志。OpenTelemetry + Jaeger 用于分布式追踪。Prometheus 指标。
控制平面
FastAPI 后端,用于 RBAC、设置、Docker 编排、模块生命周期、Agent 基础设施和带版本跟踪的 Compose 栈管理。
功能概览
网关与路由
兼容 OpenAI 的 API 端点 (/v1/*),可将请求路由到本地运行时(vLLM、llama.cpp、Ollama、TGI)和远程提供商(OpenAI、Azure 等)。基于别名的模型解析、SSE 流式传输与 TTFT 提取,以及自动重试。
安全与隐私
完整的 RBAC 与 JWT 认证、OAuth / SSO / OIDC、Redis 速率限制、并发租约和 Fernet 加密的数据库密钥。基于 Presidio 的 PII 检测,支持租户级策略、可配置的实体类型和故障安全模式。
可观测性
Langfuse 追踪与隐私模式、Loki + Alloy 集中式日志、OpenTelemetry + Jaeger 分布式追踪,以及嵌入 Grafana 面板的仪表板。每个网关请求和管理操作均有审计日志。
RAG 管道
多租户检索,支持向量、关键词和混合搜索。虚拟容器树,具有草稿/发布工作流、MinIO 预签名上传、收集器插件和通过 Taskiq + RabbitMQ 的异步处理。
运维控制台
完整的容器生命周期管理、带 SSE 进度的镜像拉取、Compose 栈部署/回滚(含版本和审计跟踪)。多厂商 GPU 自动检测(NVIDIA、AMD、Intel、Apple Metal)。
聊天控制台
内置聊天界面,支持 SSE 流式传输、拖放式会话管理、错误重试、深色/浅色主题以及按模型的使用量跟踪。支持所有通过网关连接的模型。
llm.port 对比
| 功能 | llm.port | LiteLLM | Ollama |
|---|---|---|---|
| 兼容 OpenAI 的网关 | ✅ | ✅ | ✅ |
| 管理界面 | ✅ Built-in | 💰 Paid | ❌ |
| PII 脱敏层 | ✅ Native | ❌ | ❌ |
| RAG 管道 | ✅ Built-in | ❌ | ❌ |
| Chat Console with Memory | ✅ | ❌ | ❌ |
| GPU 自动检测 | ✅ Auto-detect | ❌ | ✅ |
| Langfuse Tracing | ✅ Embedded | 🔌 Plugin | ❌ |
| Grafana + Loki Logging | ✅ Pre-configured | ❌ | ❌ |
| RBAC / 多租户 | ✅ | 💰 Partial | ❌ |
| 国际化(4 种语言) | ✅ | ❌ | ❌ |
| CLI 工具 | ✅ llmport deploy | ❌ | ❌ |
| License | Apache 2.0 | MIT + Paid | MIT |
为什么选择 llm.port
默认主权 AI — 需要时将数据保留在本地,允许时使用远程提供商,无需更改应用或失去治理和可观测性。一个平台取代了代理、仪表板和脚本的拼凑组合。
GTC 2026 企业级推理基础设施
部署 GTC 2026 上展示的模型和加速器架构的团队,需要的不仅仅是运行时 ── 他们需要一个安全网关。llm.port 提供缺失的生产层:一个兼容 OpenAI 的 API 网关,内置 PII 脱敏、RBAC 和完整可观测性 ── 全部运行在您的私有 VPC 内。数据不会离开您的边界。
- 安全 API 网关,支持速率限制、重试和基于别名的模型路由
- 入口和出口前的 PII 脱敏 ── 基于 Microsoft Presidio
- 多厂商 GPU 自动检测(NVIDIA CUDA、AMD ROCm、Intel)并自动选择 vLLM 镜像
- 企业级可观测性:Langfuse LLM 追踪、Grafana 仪表板和 OpenTelemetry
- 气隙式、主权部署 ── 无外部云依赖
路线图
高级 OCR(Docling)
IBM Docling 用于丰富的文档提取 ── 表格、图像、页面。服务框架已有;与 RAG 管道的集成正在进行中。
认证服务(SSO / OIDC)
专用认证服务,用于外部身份提供商管理。框架和 Compose 配置已定义。
邮件服务
专用邮件发送服务,用于密码重置、管理员提醒和系统邀请。
企业版 Pro 模块
许可框架已就绪(Ed25519 JWT)。PII、RAG 和网关的 Pro 实现即将推出。
更多运行时
TensorRT-LLM、SGLang 及更多托管 API 提供商。
精细化成本控制
按租户、模型和用户的使用量分析,支持预算限制和成本分摊。
界面截图
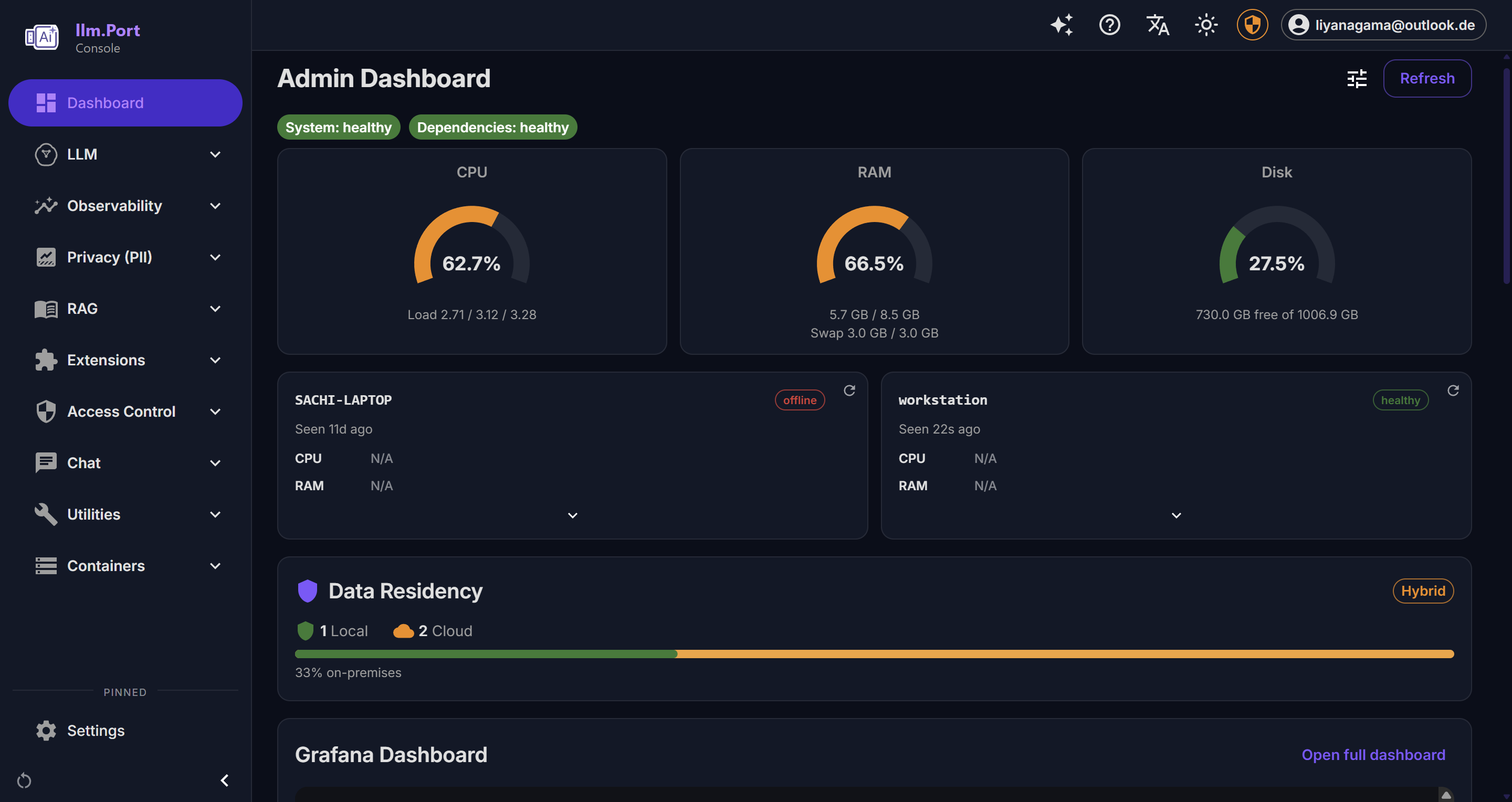 Dashboard
Dashboard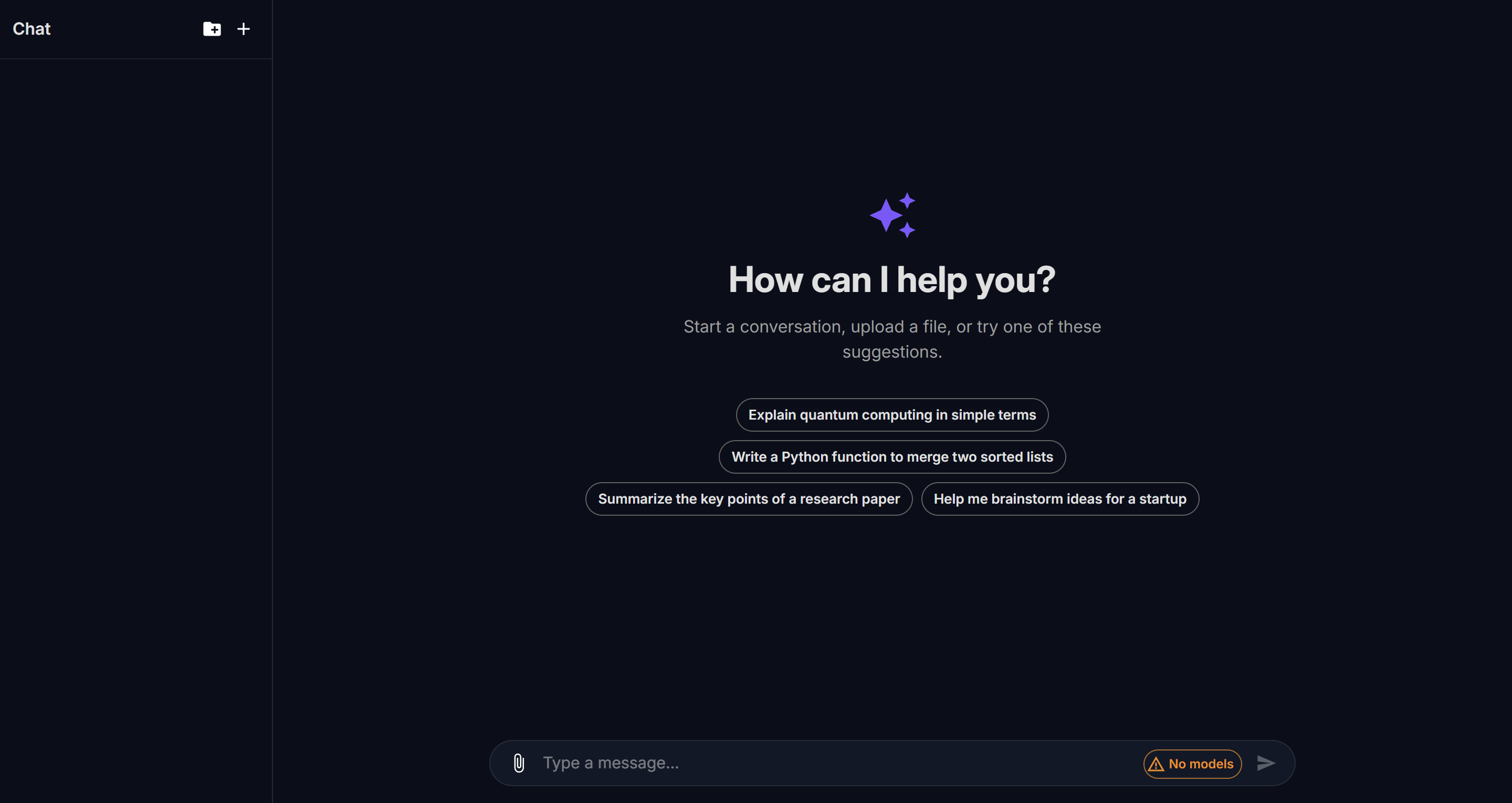 Chat Console
Chat Console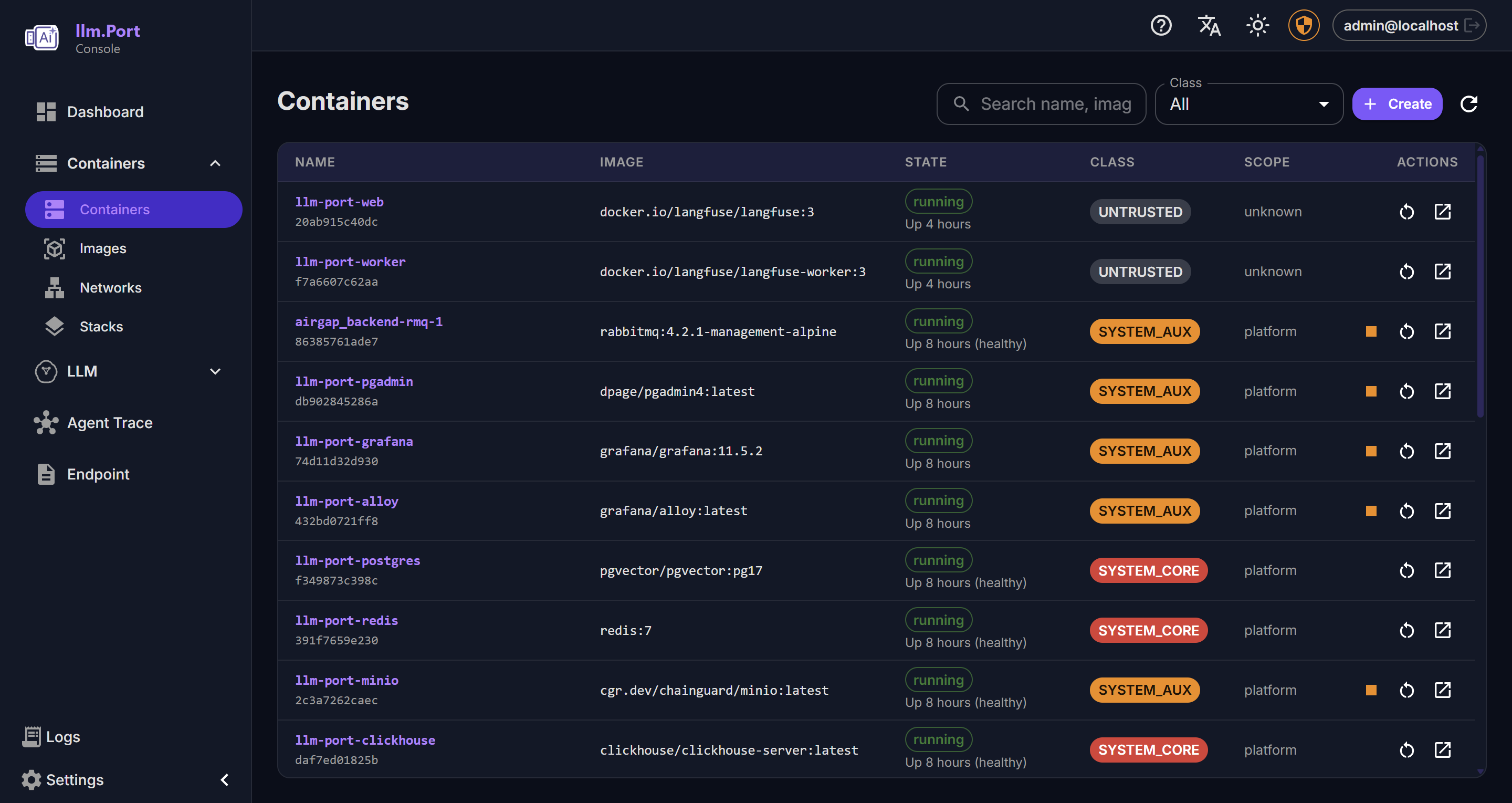 Container Management
Container Management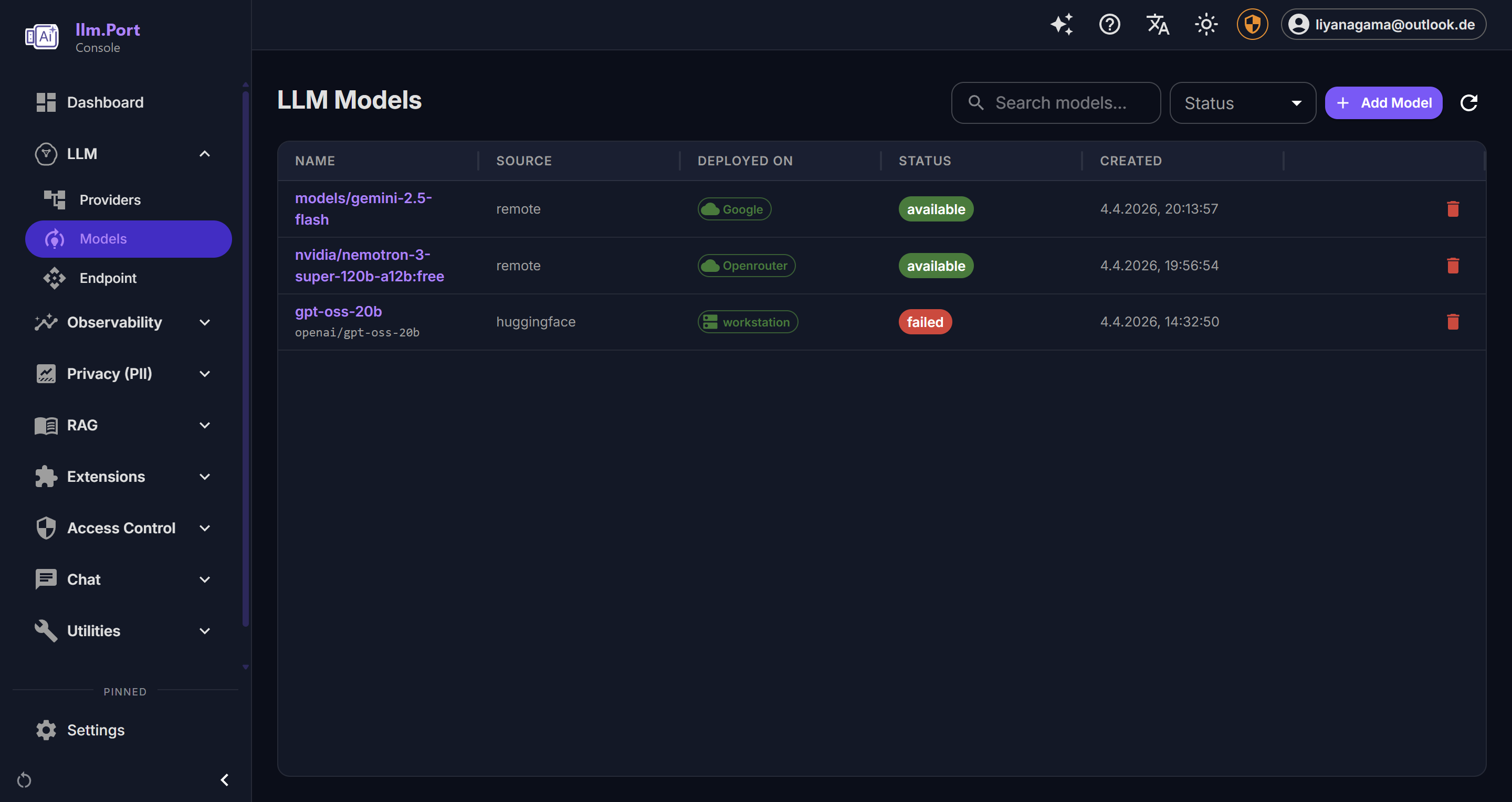 LLM Providers
LLM Providers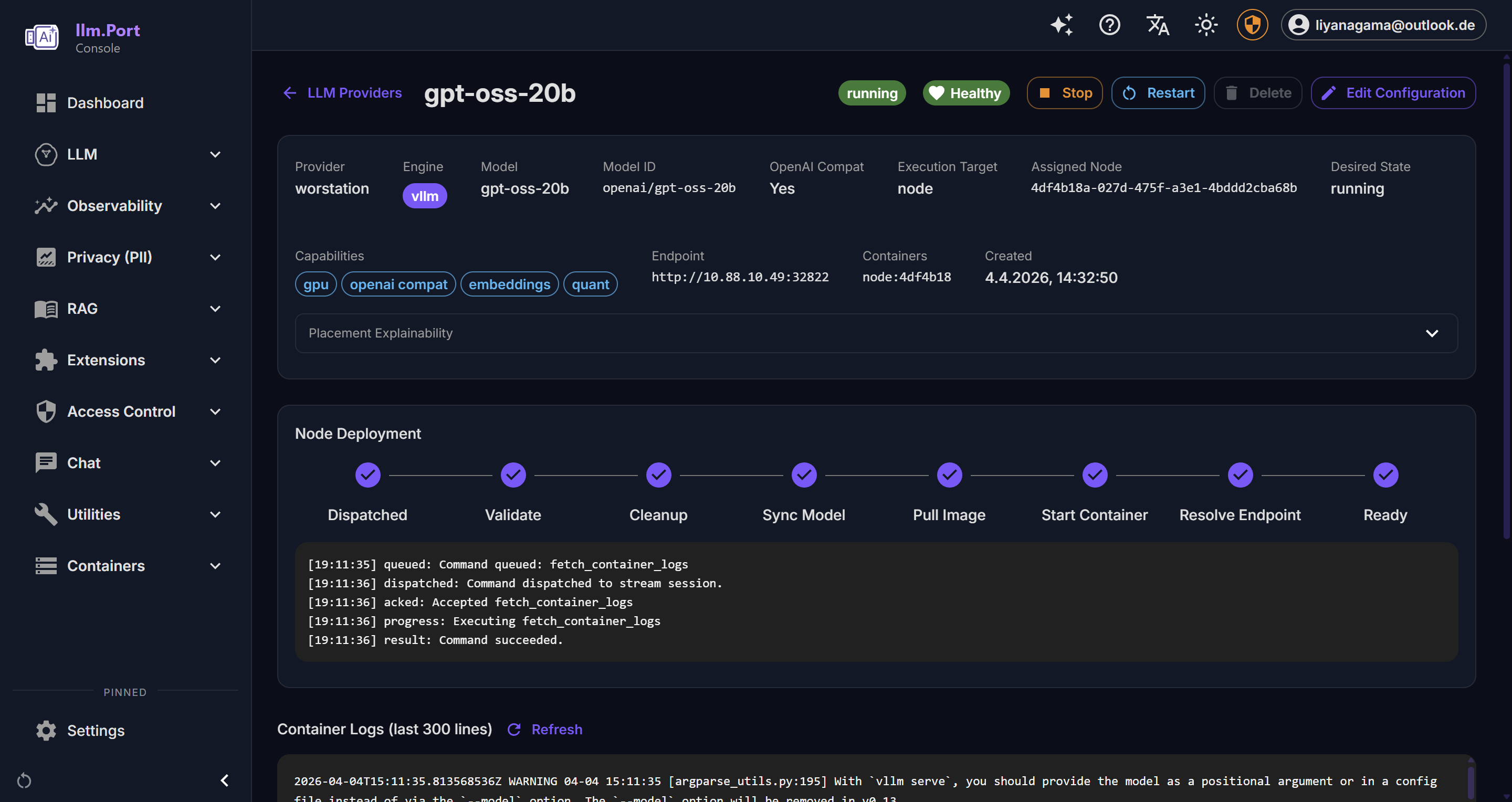 Provider Details
Provider Details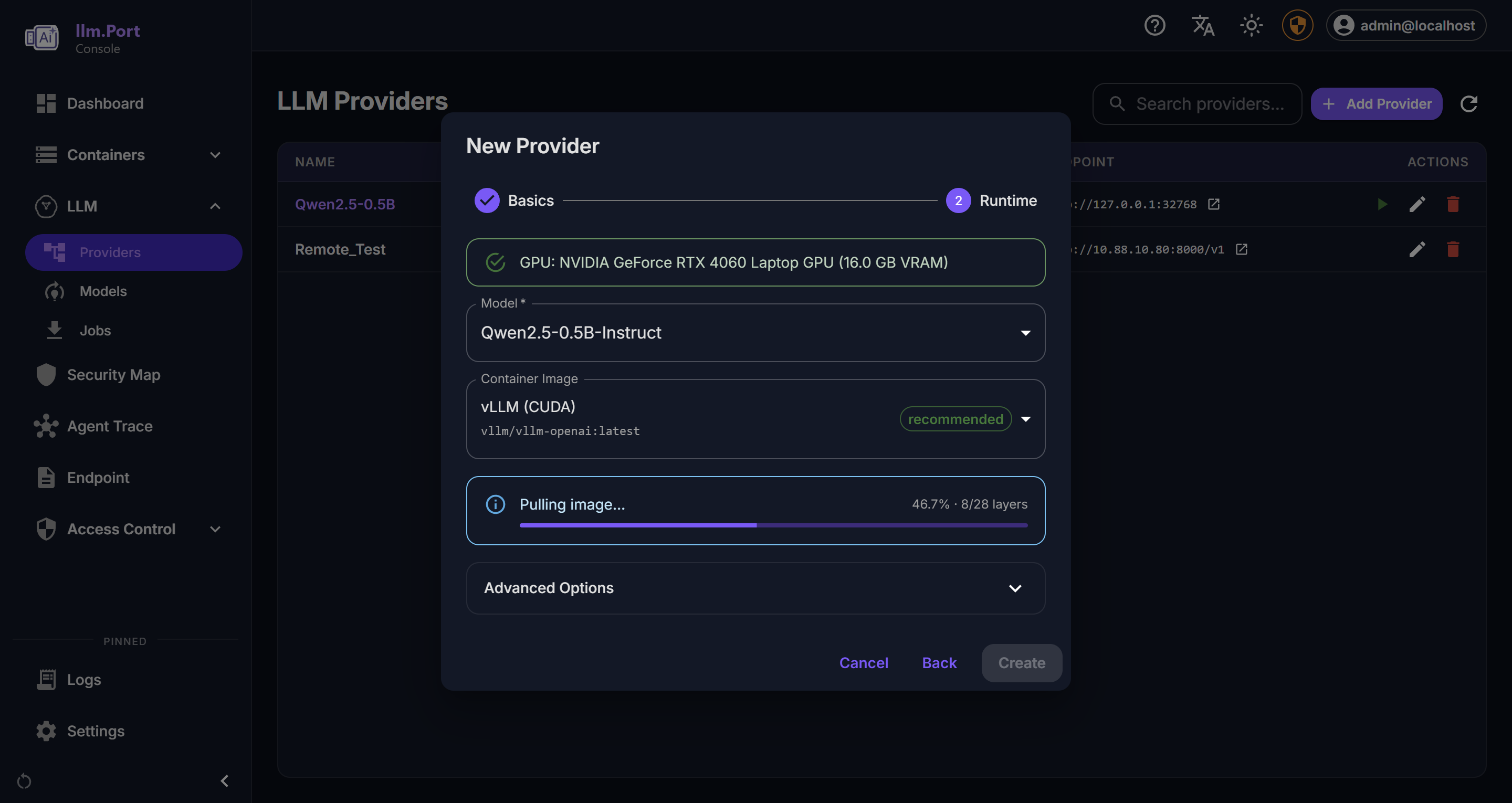 Local Runtime
Local Runtime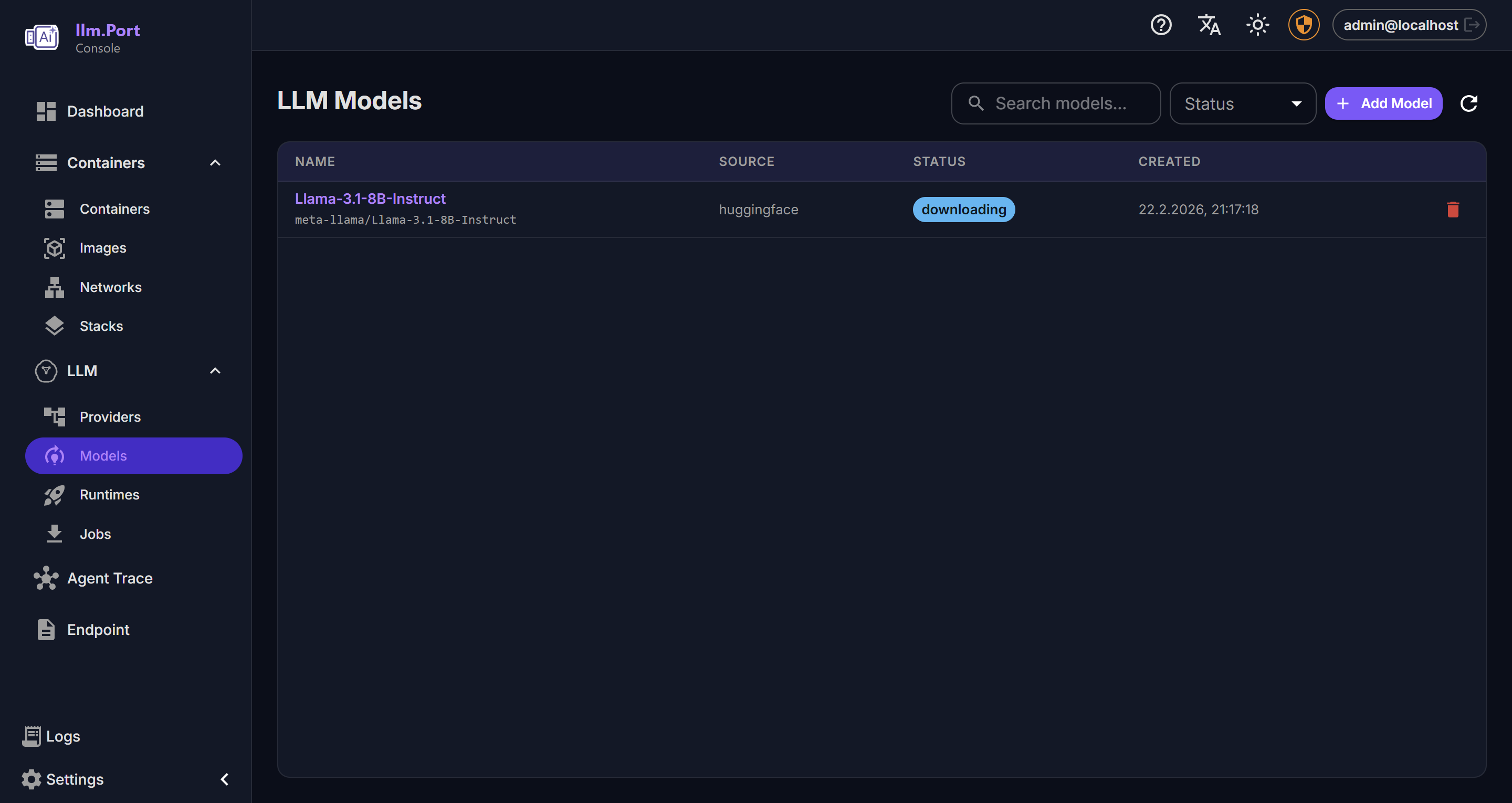 Models
Models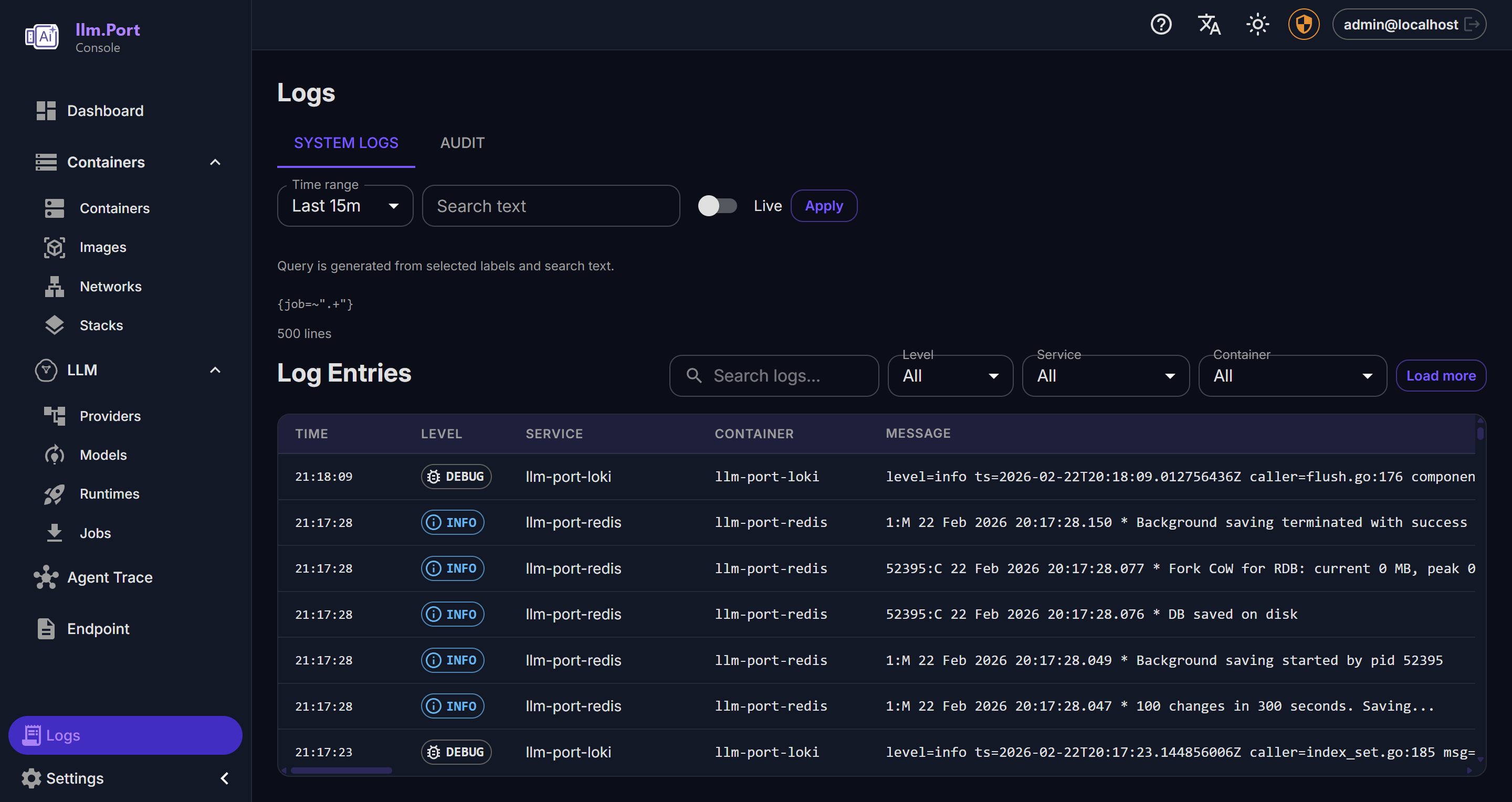 Logging
Logging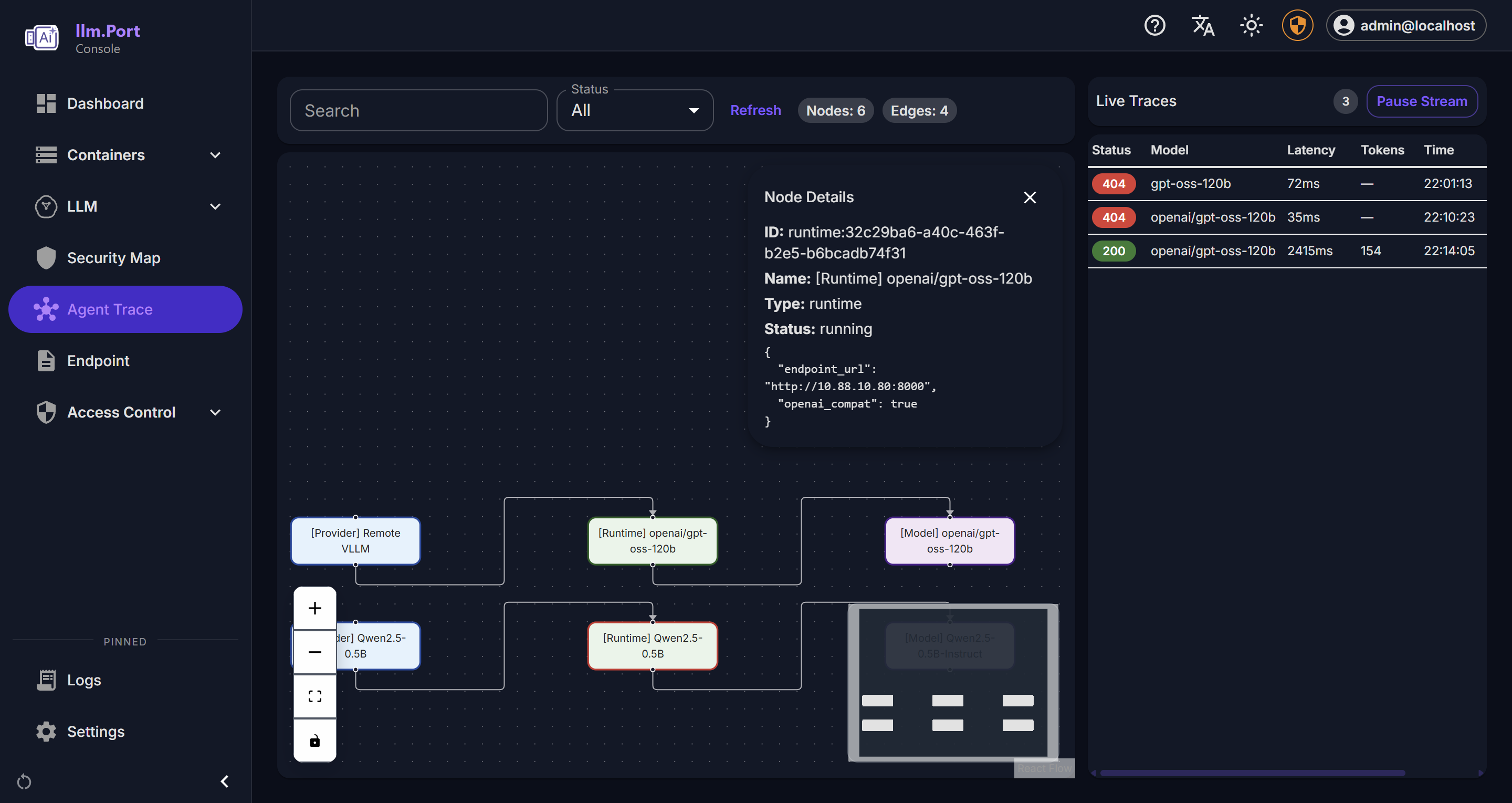 Trace Viewer
Trace Viewer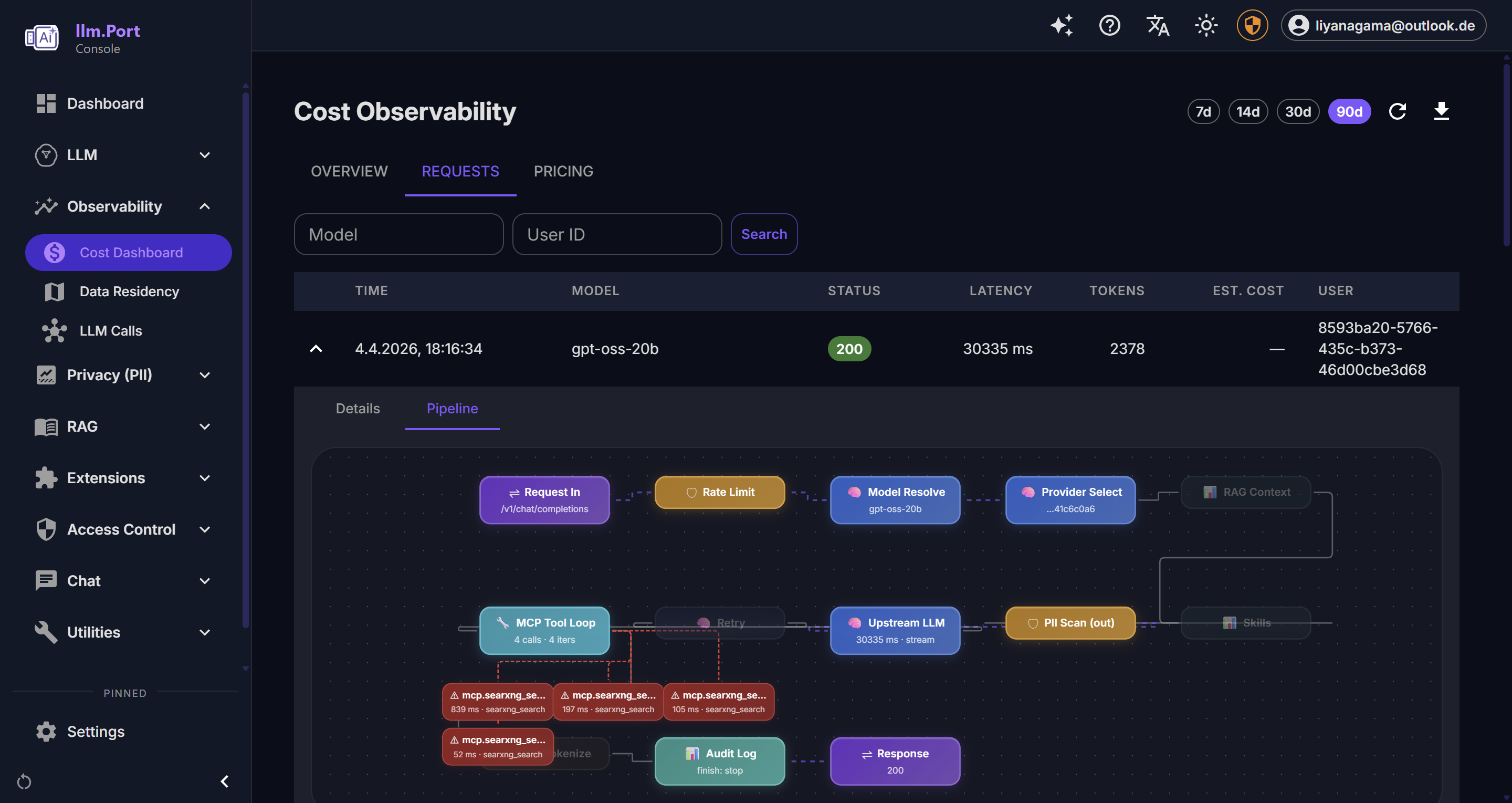 Cost & Request Trends
Cost & Request Trends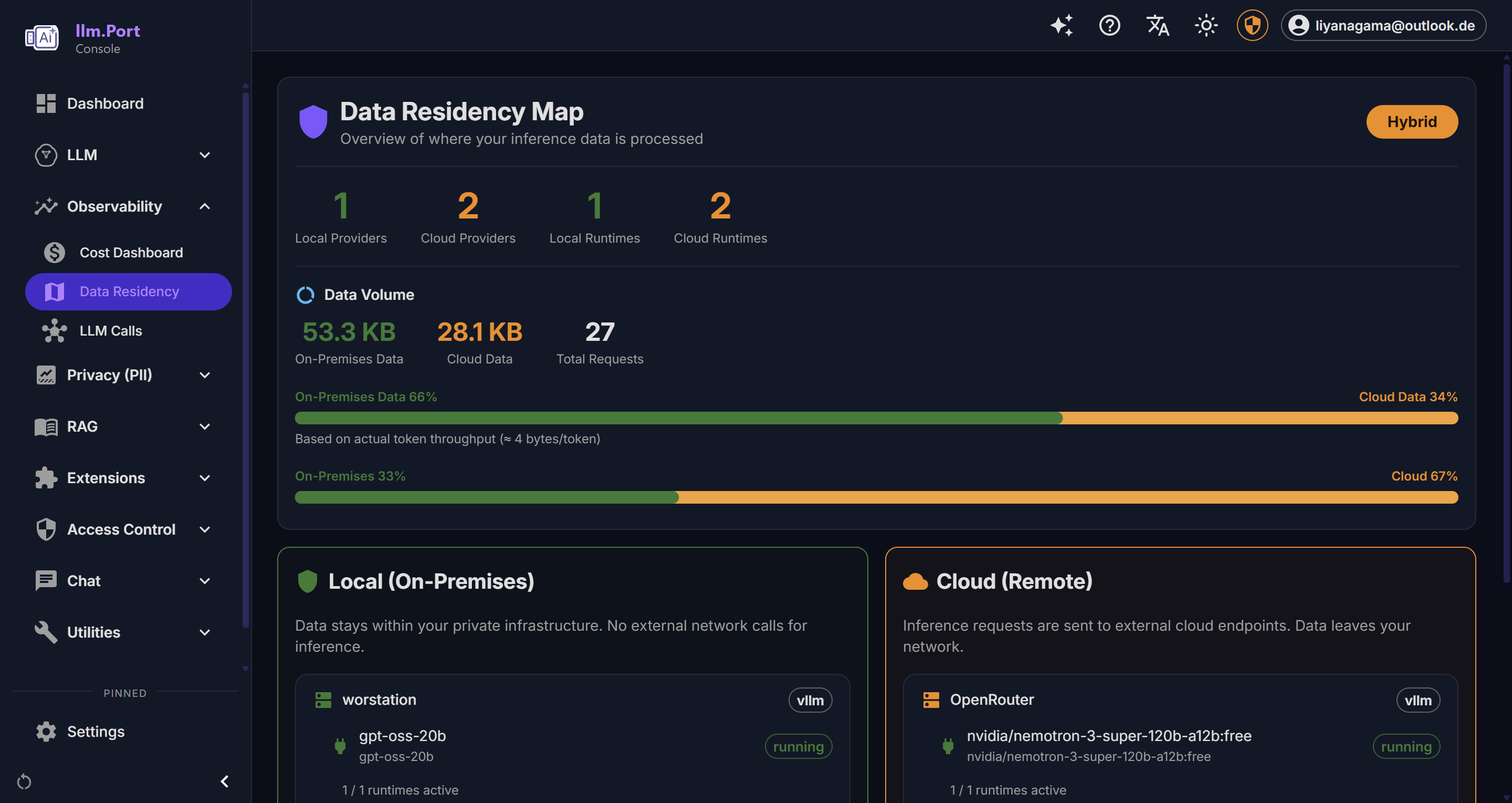 Security Overview
Security Overview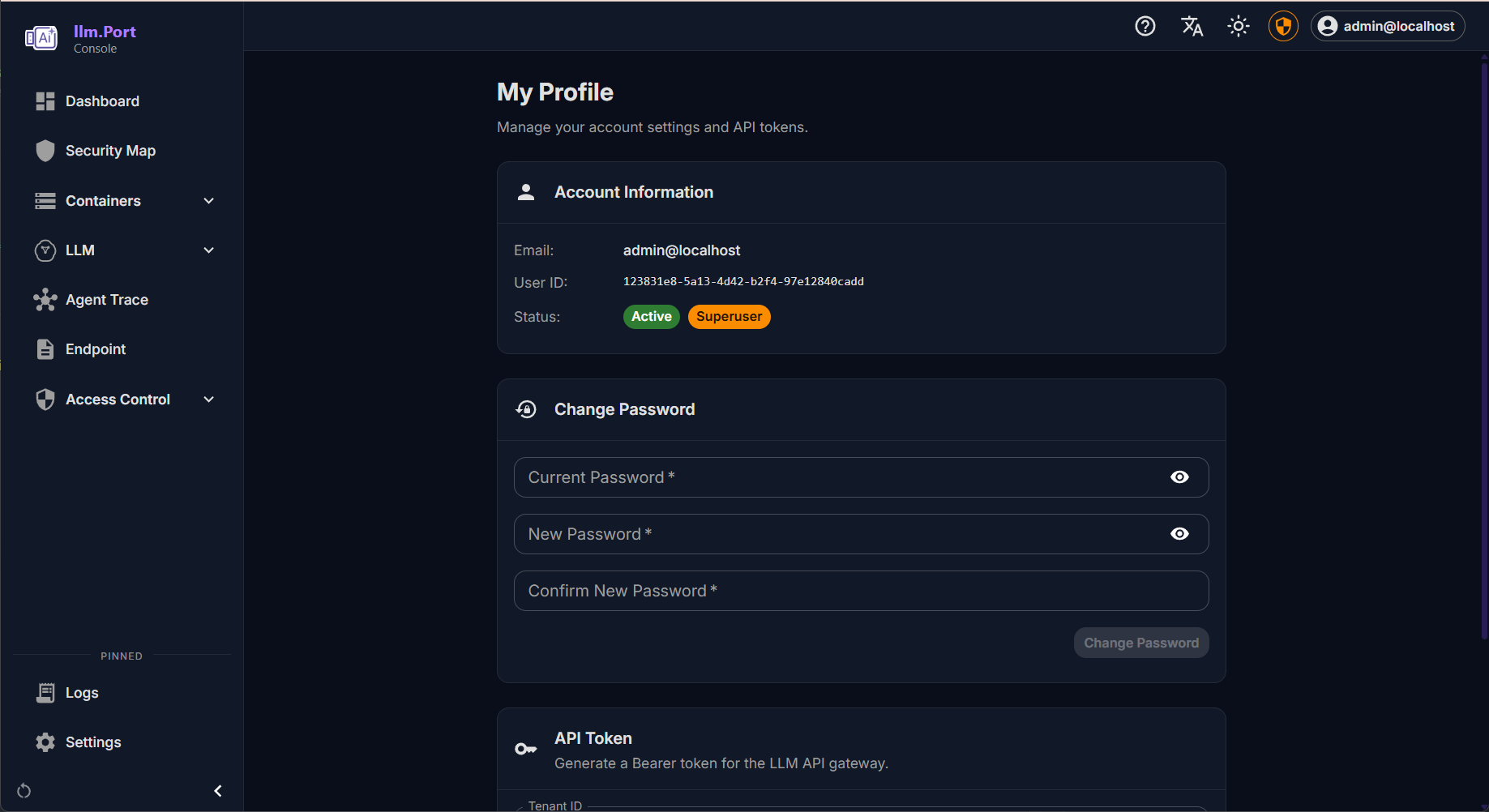 User Profile
User Profile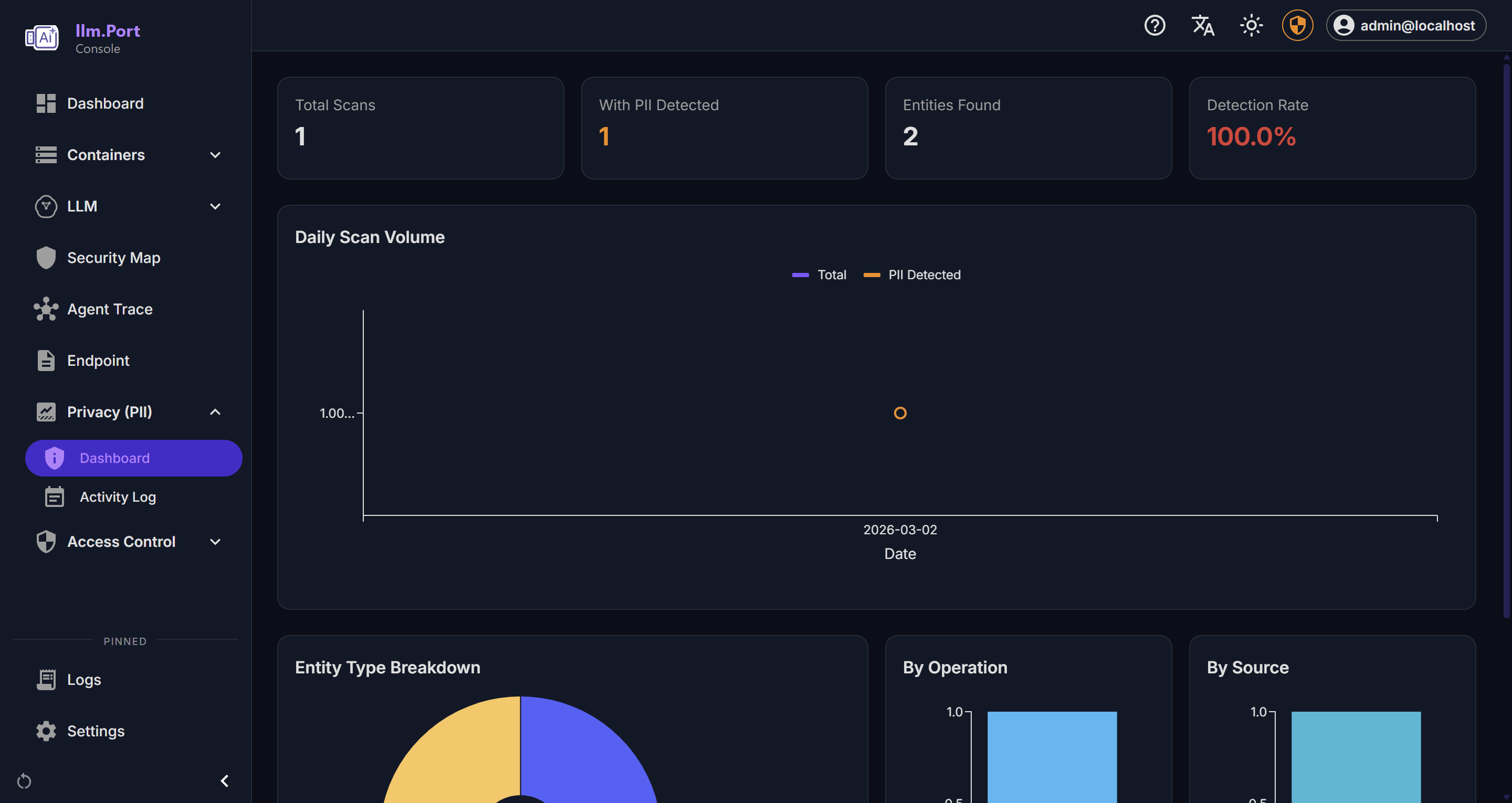 PII Detection
PII Detection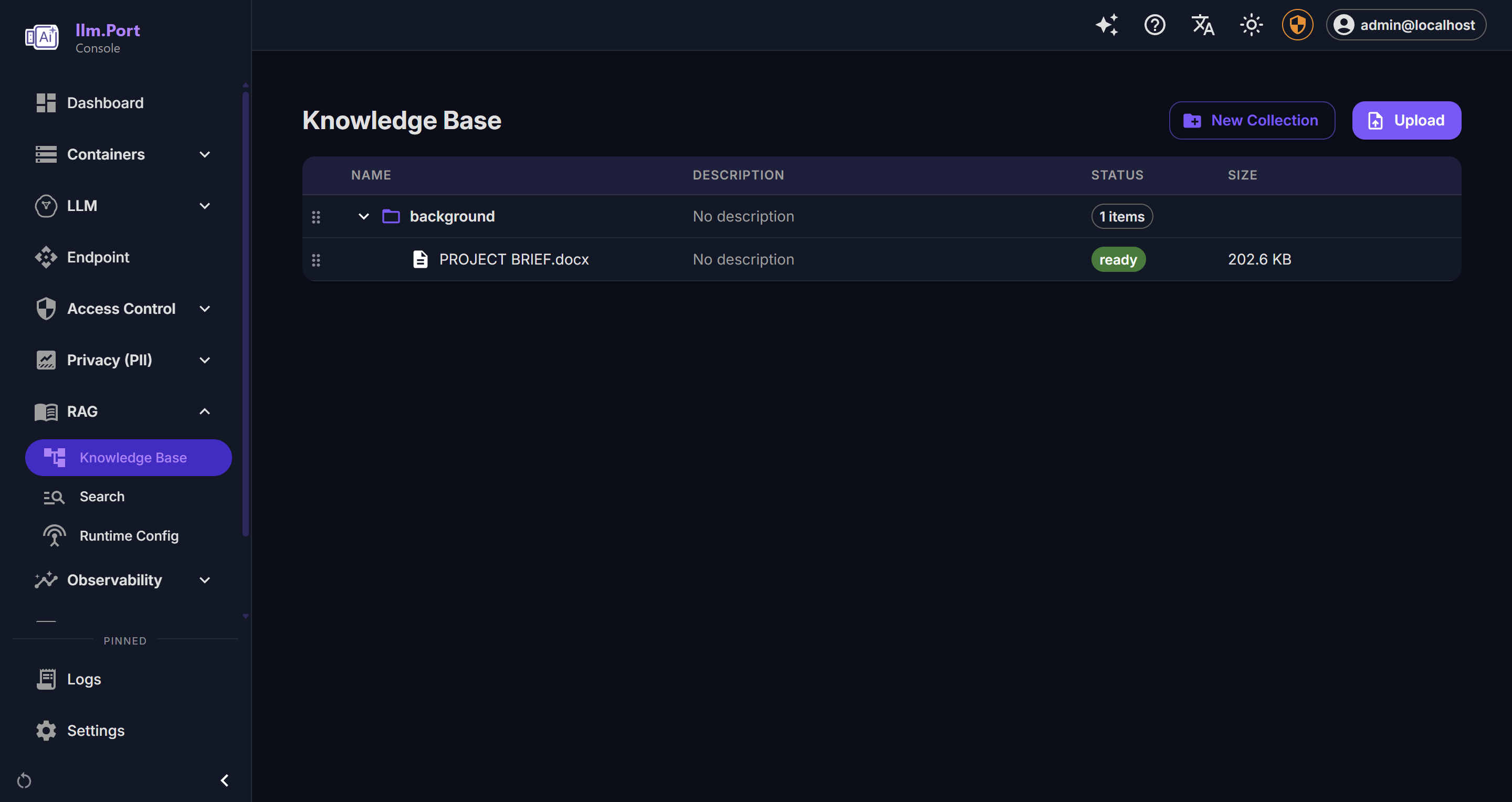 Knowledge Base
Knowledge Base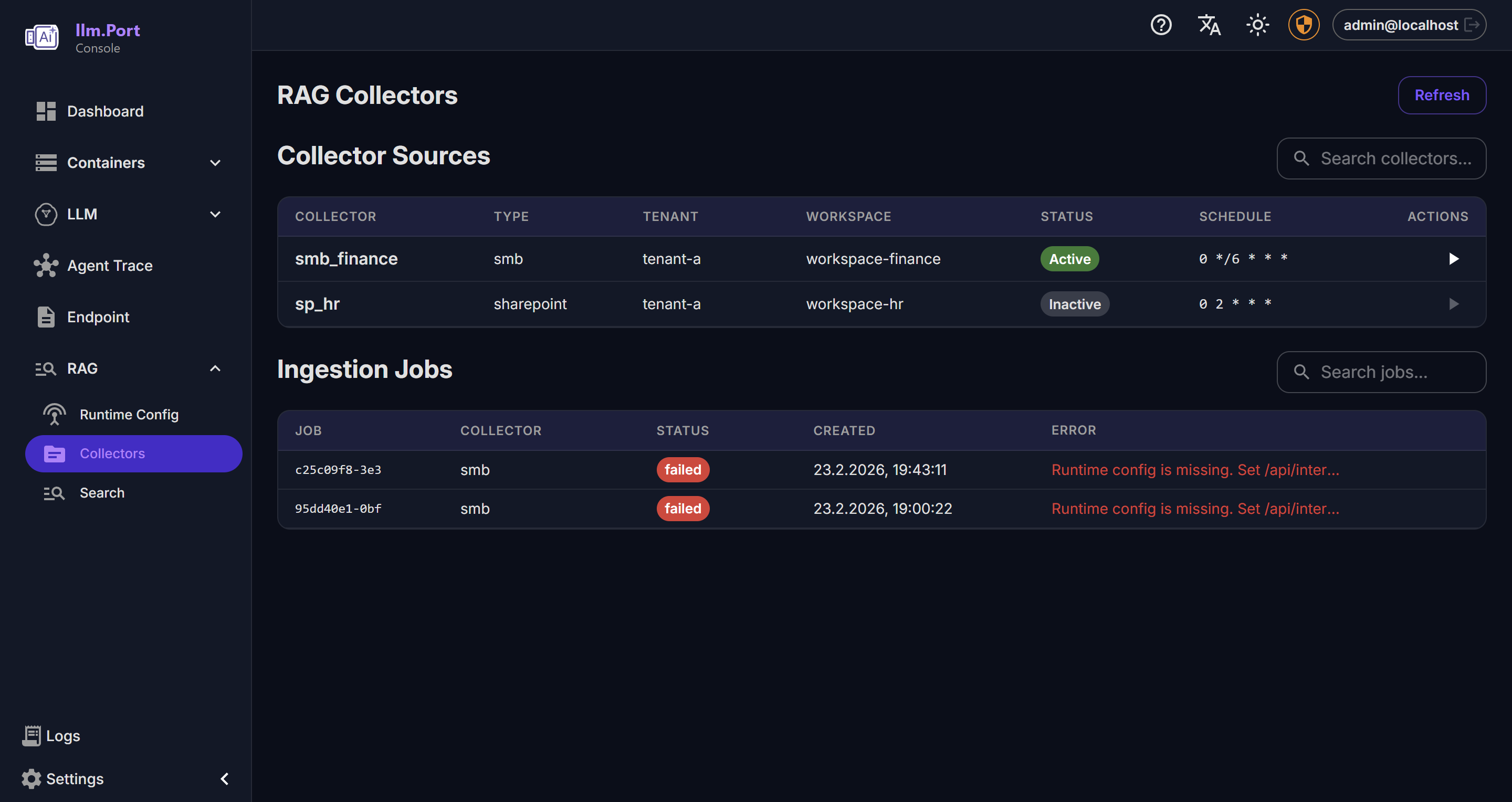 RAG Collectors
RAG Collectors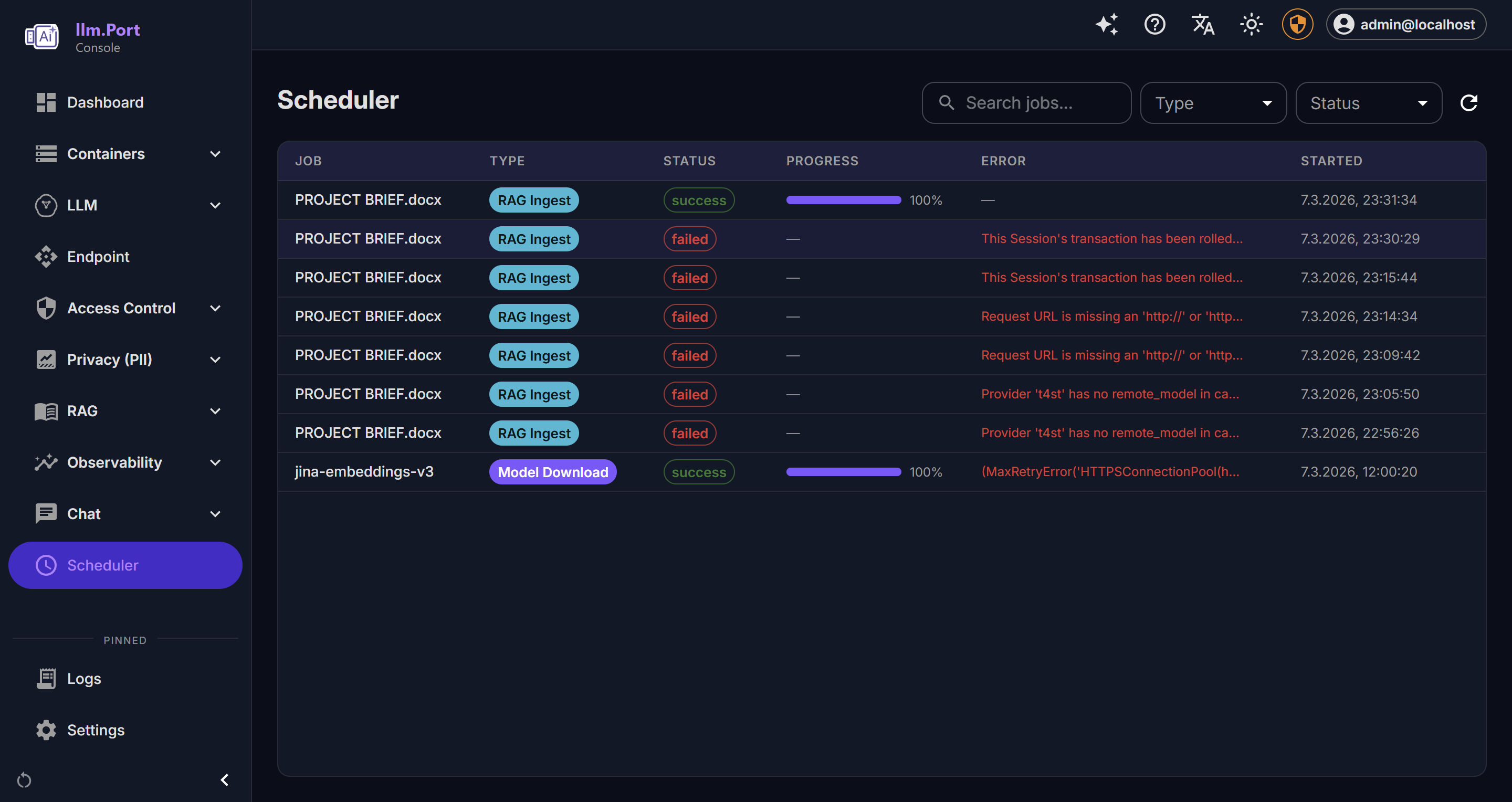 Scheduled Publishing
Scheduled Publishing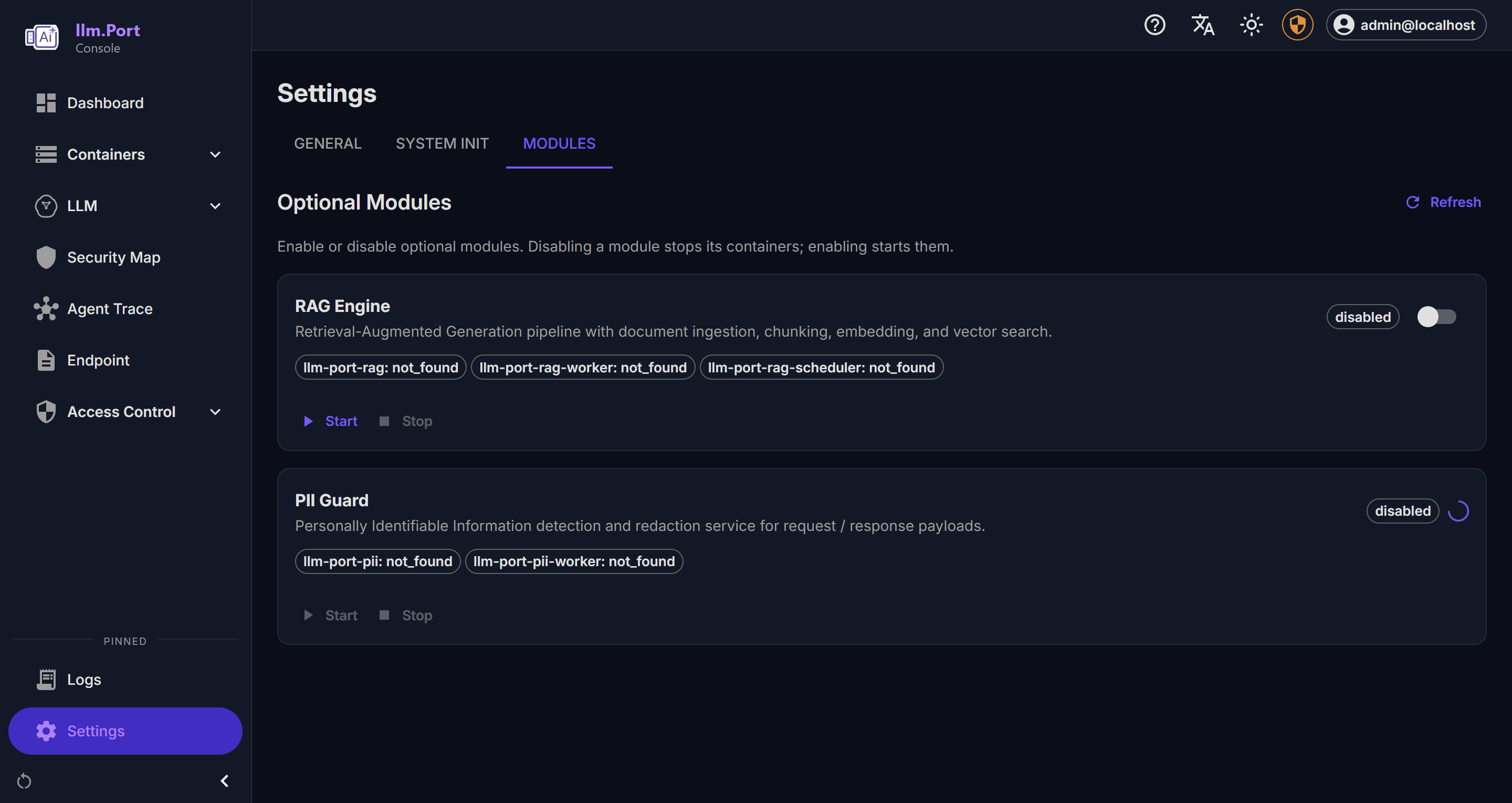 Modules
Modules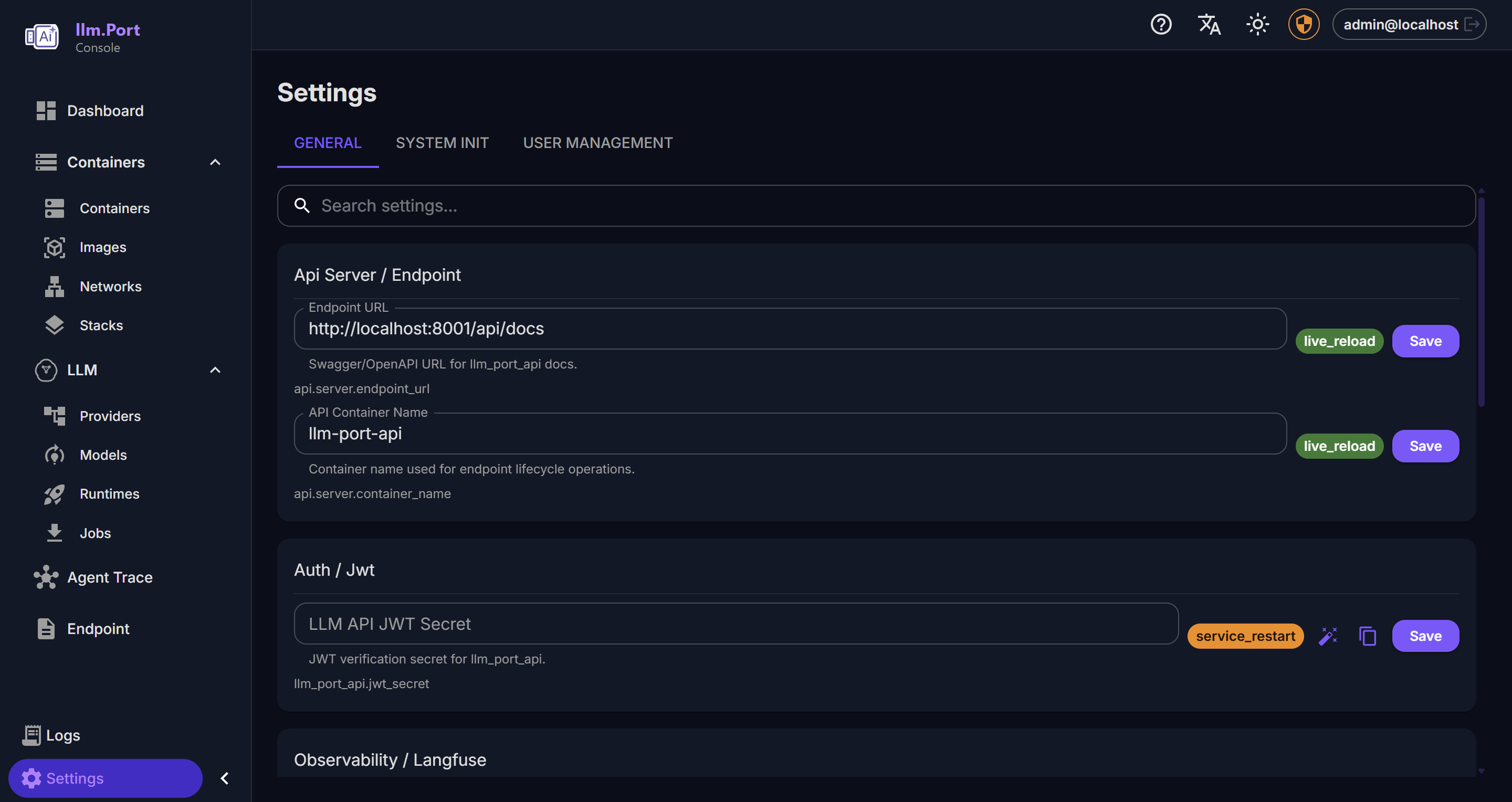 Settings
Settings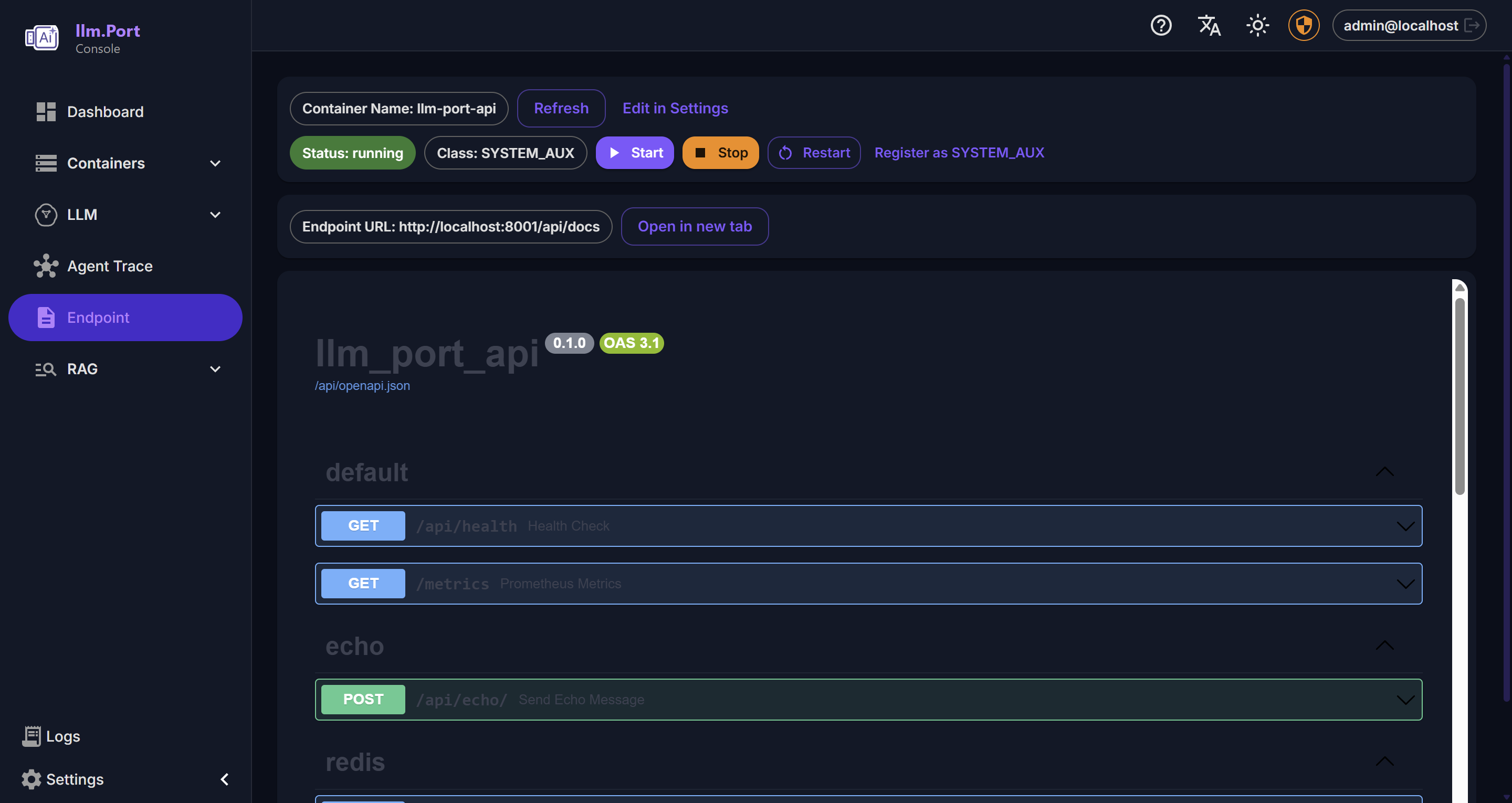 API Playground
API Playground企业版功能可用 适用于需要 SSO、高级 PII 令牌化和治理的团队。 联系我们 →