llm.Port
Self-hosted all-in-one LLM platform
Routes, secures, and observes traffic across local LLM runtimes and remote providers — giving teams a single place to manage LLM services end-to-end.
# Install the CLI
$ pip install llmport-cli
# Check prerequisites & deploy
$ llmport doctor
$ llmport deploy
# Enable optional modules
$ llmport module enable pii
$ llmport module enable ragAvailable in English, Deutsch, Español, 中文
How it Works
API Gateway
OpenAI-compatible /v1/* endpoint. Routes to vLLM, llama.cpp, Ollama, TGI and remote providers (OpenAI, Azure, …). SSE streaming, alias-based model resolution, retry, and rate limiting.
PII Layer
Microsoft Presidio integration for real-time detection and redaction. Per-tenant policies with configurable entity types and fail-safe modes.
GPU Orchestration
Auto-detects NVIDIA (CUDA), AMD (ROCm), and Intel GPUs. Spawns vLLM containers with the correct image (CUDA / ROCm / Legacy). HuggingFace cache mounting for fast model loading.
Storage
PostgreSQL with pgvector for vector search (RAG). Redis for rate limiting, session cache, and distributed leasing. MinIO for S3-compatible document storage.
Observability
Langfuse for LLM tracing with privacy modes. Grafana + Loki + Alloy for centralized logging. OpenTelemetry + Jaeger for distributed tracing. Prometheus metrics.
Control Plane
FastAPI backend for RBAC, settings, Docker orchestration, module lifecycle, agent infra, and Compose stack management with revision tracking.
What it does
Gateway & Routing
OpenAI-compatible API endpoint (/v1/*) that routes to local runtimes (vLLM, llama.cpp, Ollama, TGI) and remote providers (OpenAI, Azure, …). Alias-based model resolution, SSE streaming with TTFT extraction, and automatic retry.
Security & PII
Full RBAC with JWT authentication, OAuth / SSO / OIDC, Redis rate limiting, concurrency leasing, and Fernet-encrypted DB secrets. Presidio-based PII detection with per-tenant policies, configurable entity types, and fail-safe modes.
Observability
Langfuse tracing with privacy modes, Loki + Alloy centralized logging, OpenTelemetry + Jaeger distributed tracing, and a dashboard with Grafana panel embeds. Every gateway request and admin action is audit-logged.
RAG Pipeline
Multi-tenant retrieval with vector, keyword, and hybrid search. Virtual container tree with draft/publish workflows, presigned MinIO uploads, collector plugins, and async processing via Taskiq + RabbitMQ.
Ops Console
Full container lifecycle management, image pulls with SSE progress, Compose stack deploy/rollback with revisions and audit trail. Multi-vendor GPU auto-detection (NVIDIA, AMD, Intel, Apple Metal).
Chat Console
Built-in chat UI with SSE streaming, drag-and-drop session management, error retry, dark / light theming, and per-model usage tracking. Supports all gateway-connected models.
How llm.port Compares
| Feature | llm.port | LiteLLM | Ollama |
|---|---|---|---|
| OpenAI-compatible gateway | ✅ | ✅ | ✅ |
| Admin UI | ✅ Built-in | 💰 Paid | ❌ |
| PII redaction layer | ✅ Native | ❌ | ❌ |
| RAG pipeline | ✅ Built-in | ❌ | ❌ |
| Chat Console with Memory | ✅ | ❌ | ❌ |
| GPU auto-detection | ✅ Auto-detect | ❌ | ✅ |
| Langfuse Tracing | ✅ Embedded | 🔌 Plugin | ❌ |
| Grafana + Loki Logging | ✅ Pre-configured | ❌ | ❌ |
| RBAC / multi-tenant | ✅ | 💰 Partial | ❌ |
| i18n (4 languages) | ✅ | ❌ | ❌ |
| CLI tooling | ✅ llmport deploy | ❌ | ❌ |
| License | Apache 2.0 | MIT + Paid | MIT |
Why llm.port
Sovereign-by-default AI — keep data on-prem when needed, use remote providers when allowed, without changing your apps or losing governance and observability. One platform replaces a patchwork of proxies, dashboards, and scripts.
GTC 2026 Inference Infrastructure for the Enterprise
Teams deploying the models and accelerator architectures showcased at GTC 2026 need more than a runtime — they need a secure gateway. llm.port provides the missing production layer: an OpenAI-compatible API gateway with built-in PII redaction, RBAC, and full observability — all running inside your private VPC. No data leaves your perimeter.
- Secure API gateway with rate limiting, retry, and alias-based model routing
- PII redaction before ingress and egress — Microsoft Presidio-powered
- Multi-vendor GPU auto-detection (NVIDIA CUDA, AMD ROCm, Intel) with automatic vLLM image selection
- Enterprise observability: Langfuse LLM tracing, Grafana dashboards, and OpenTelemetry
- Air-gapped, sovereign deployment — no external cloud dependency
Roadmap
Advanced OCR (Docling)
IBM Docling for rich document extraction — tables, images, pages. Service scaffold exists; integration with RAG pipeline in progress.
Auth Service (SSO / OIDC)
Dedicated auth service for external identity provider management. Framework and compose profile defined.
Mailer Service
Dedicated email delivery service for password resets, admin alerts, and system invites.
Enterprise Pro Modules
License framework ready (Ed25519 JWT). Pro implementations for PII, RAG, and Gateway coming soon.
More Runtimes
TensorRT-LLM, SGLang, and additional managed API providers.
Fine-grained Cost Controls
Usage analytics per tenant, model, and user with budget limits and chargeback support.
Screenshots
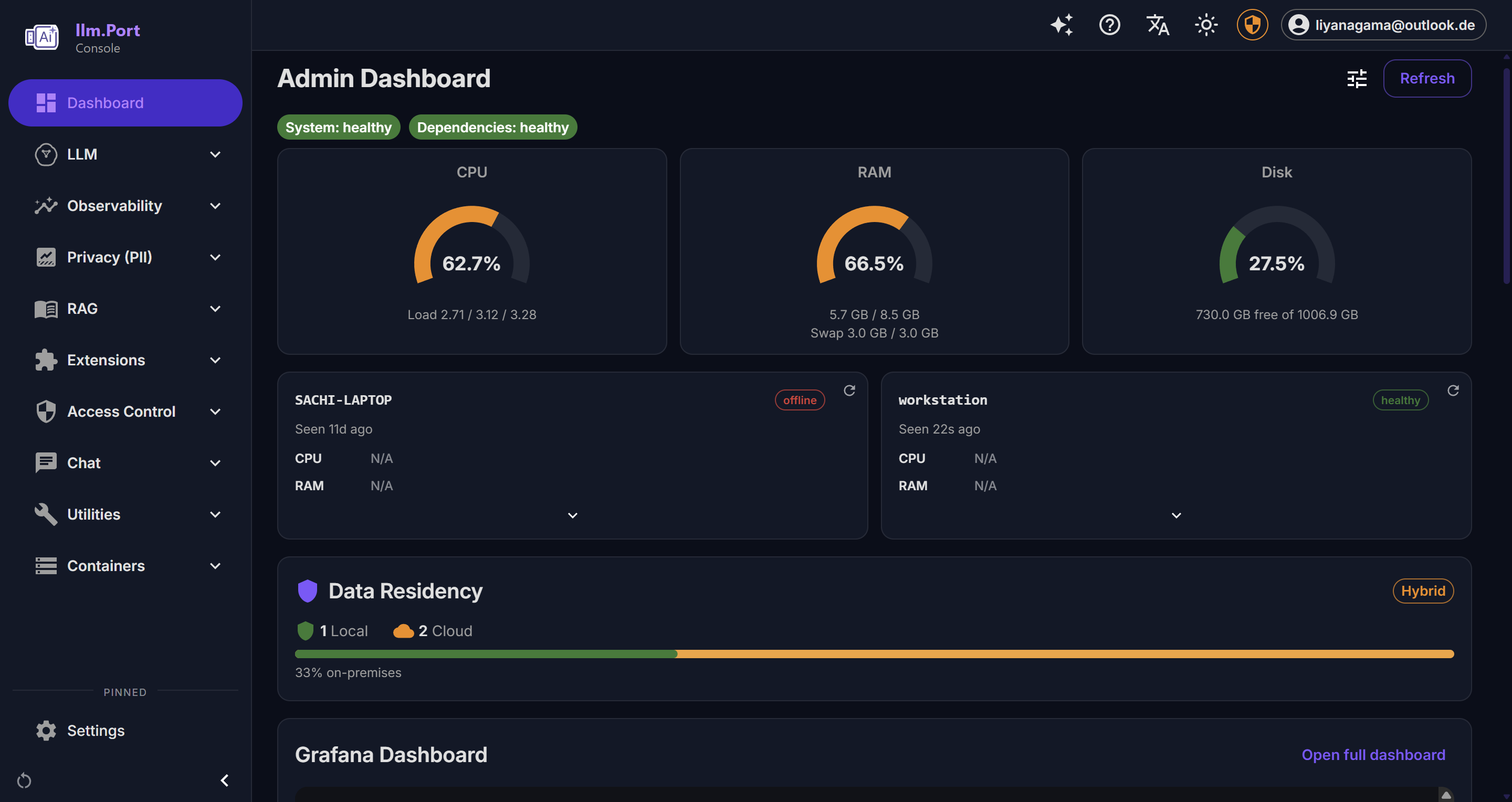 Dashboard
Dashboard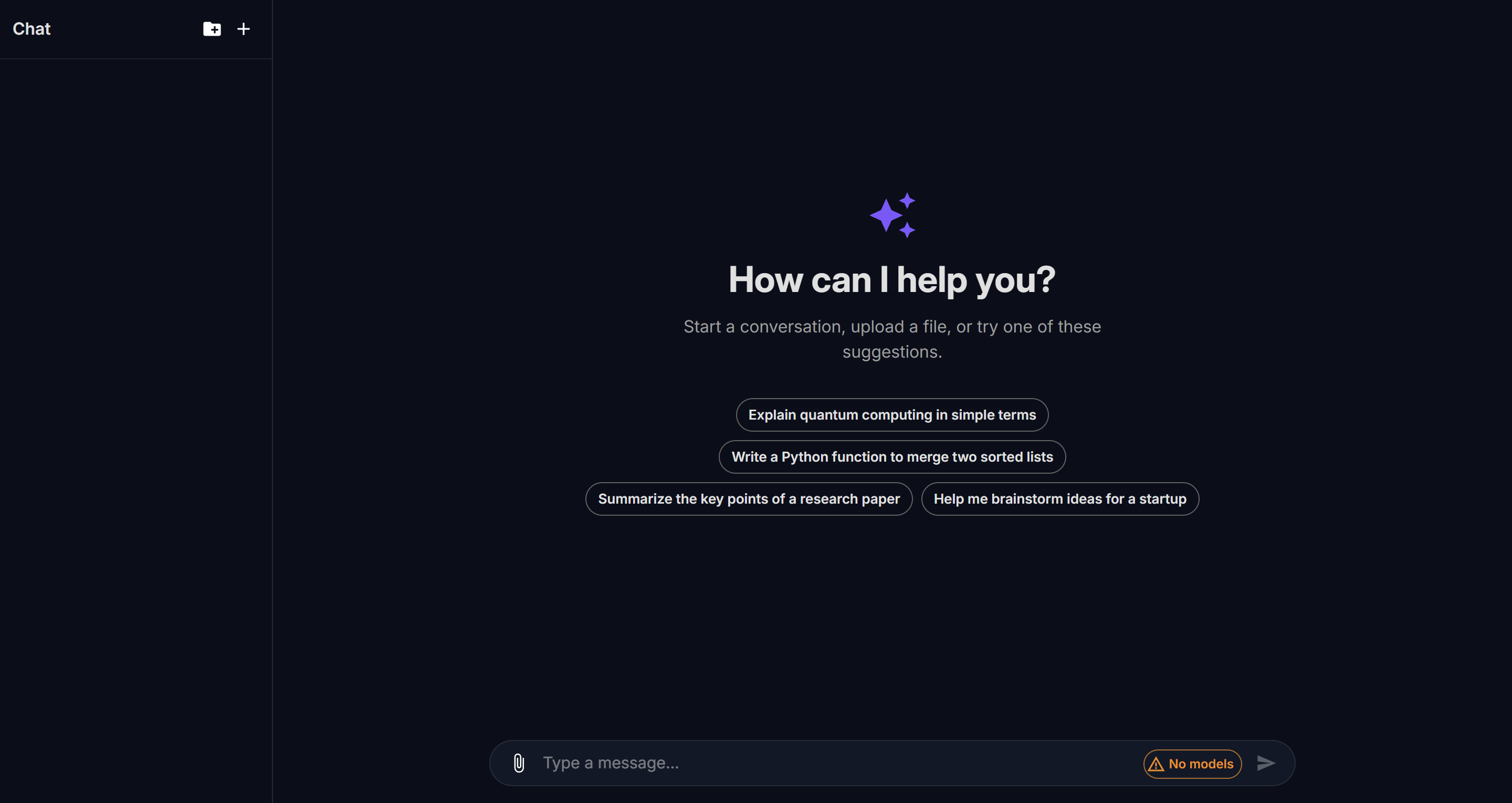 Chat Console
Chat Console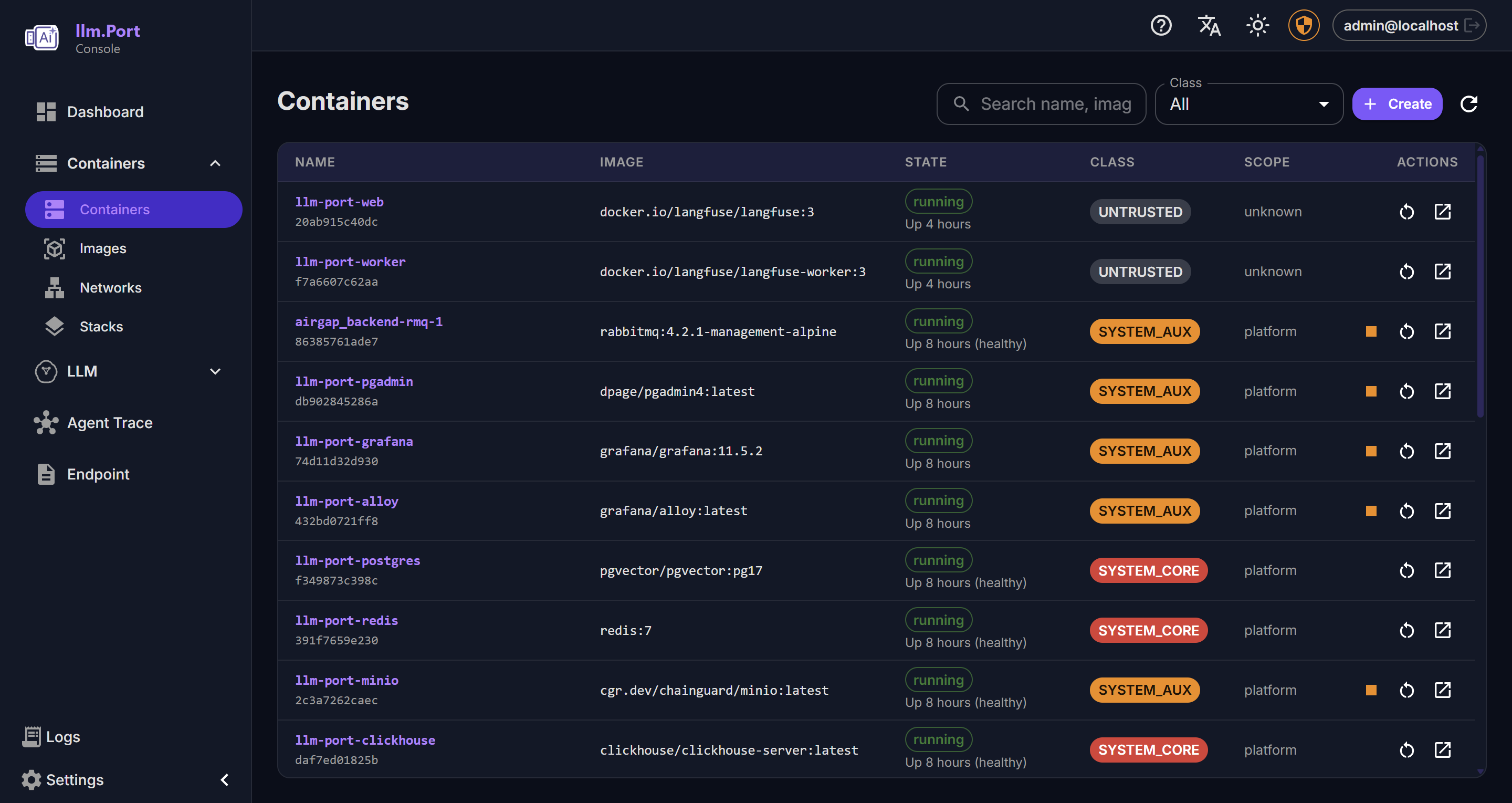 Container Management
Container Management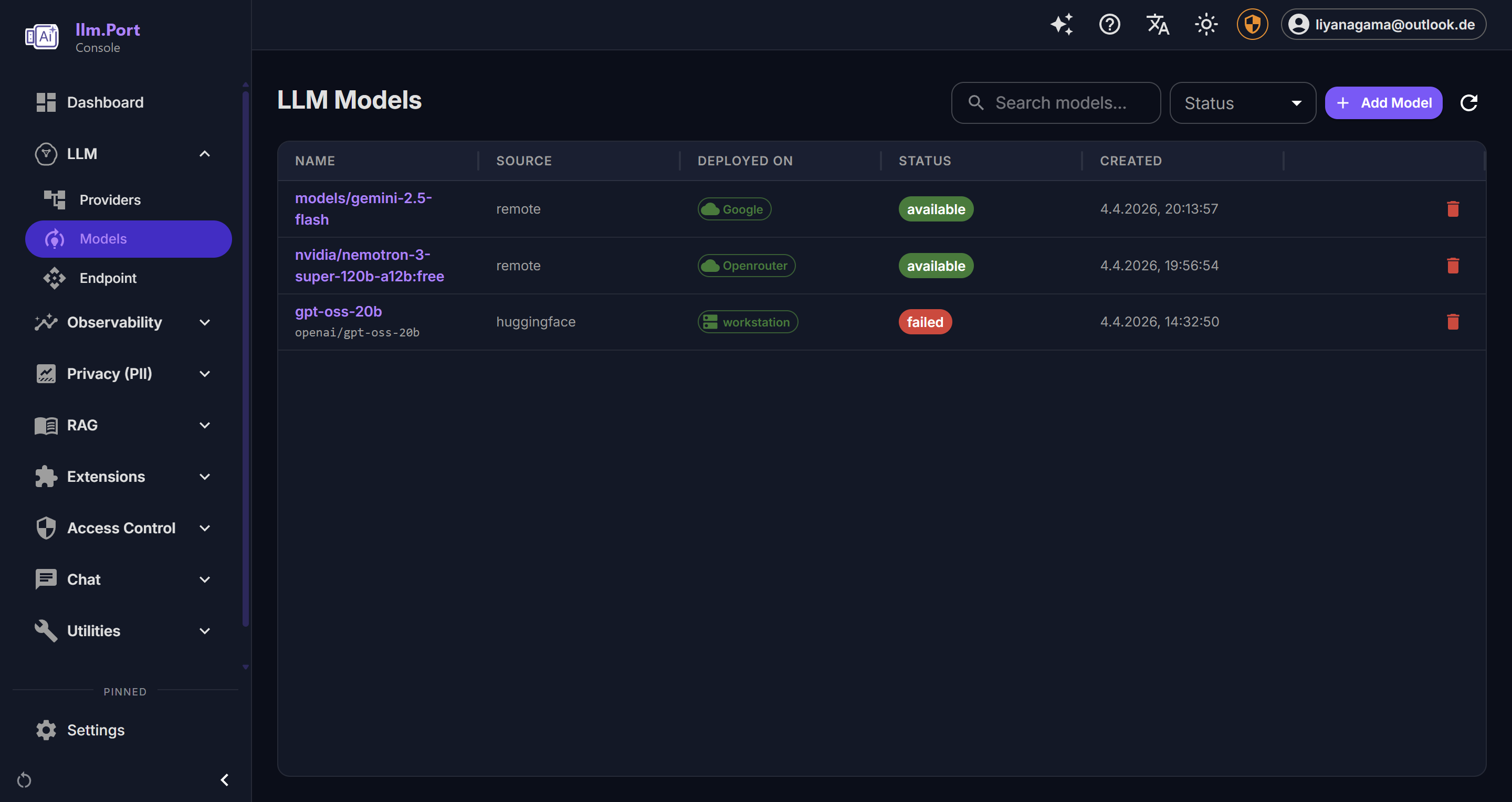 LLM Providers
LLM Providers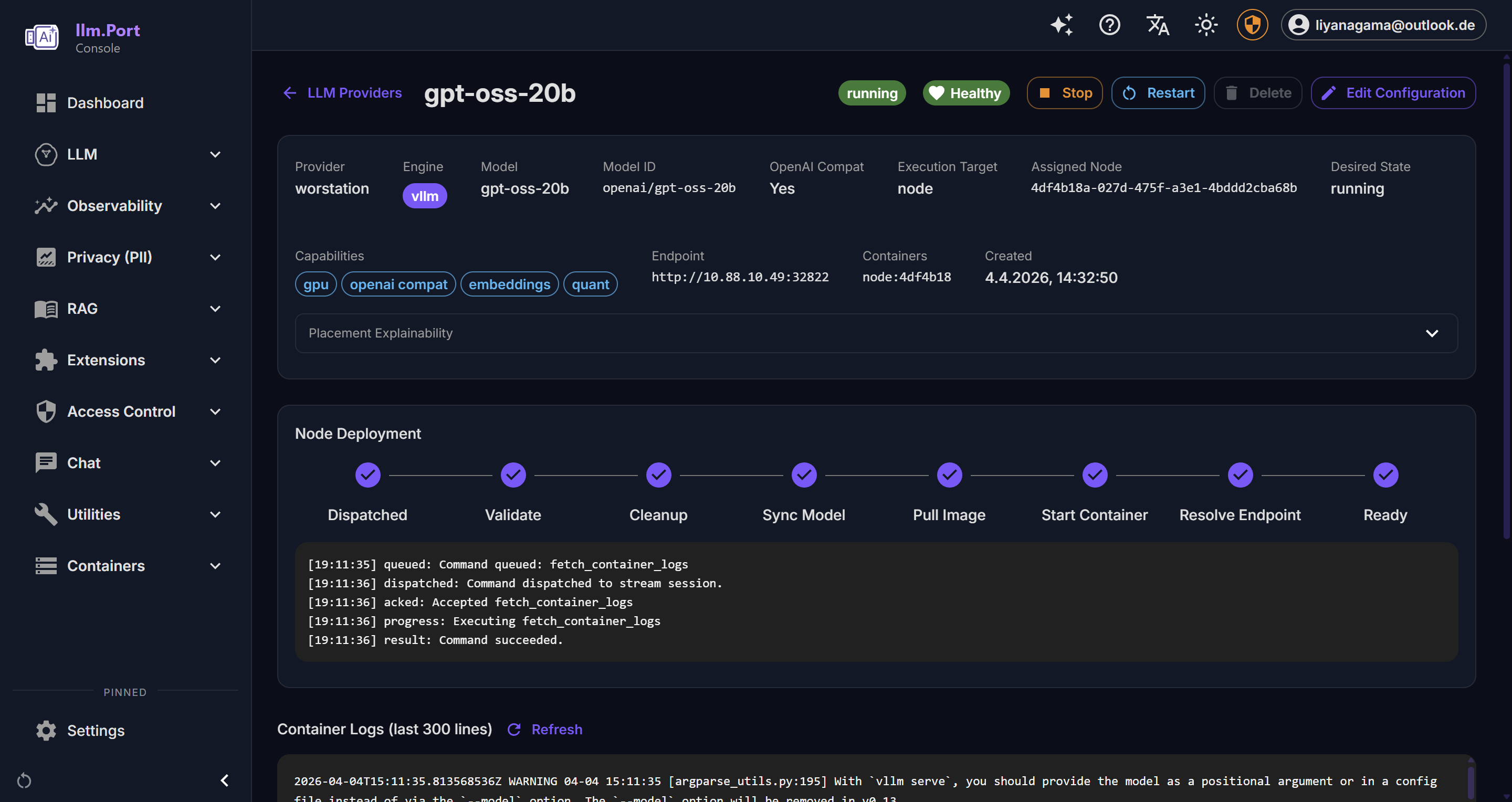 Provider Details
Provider Details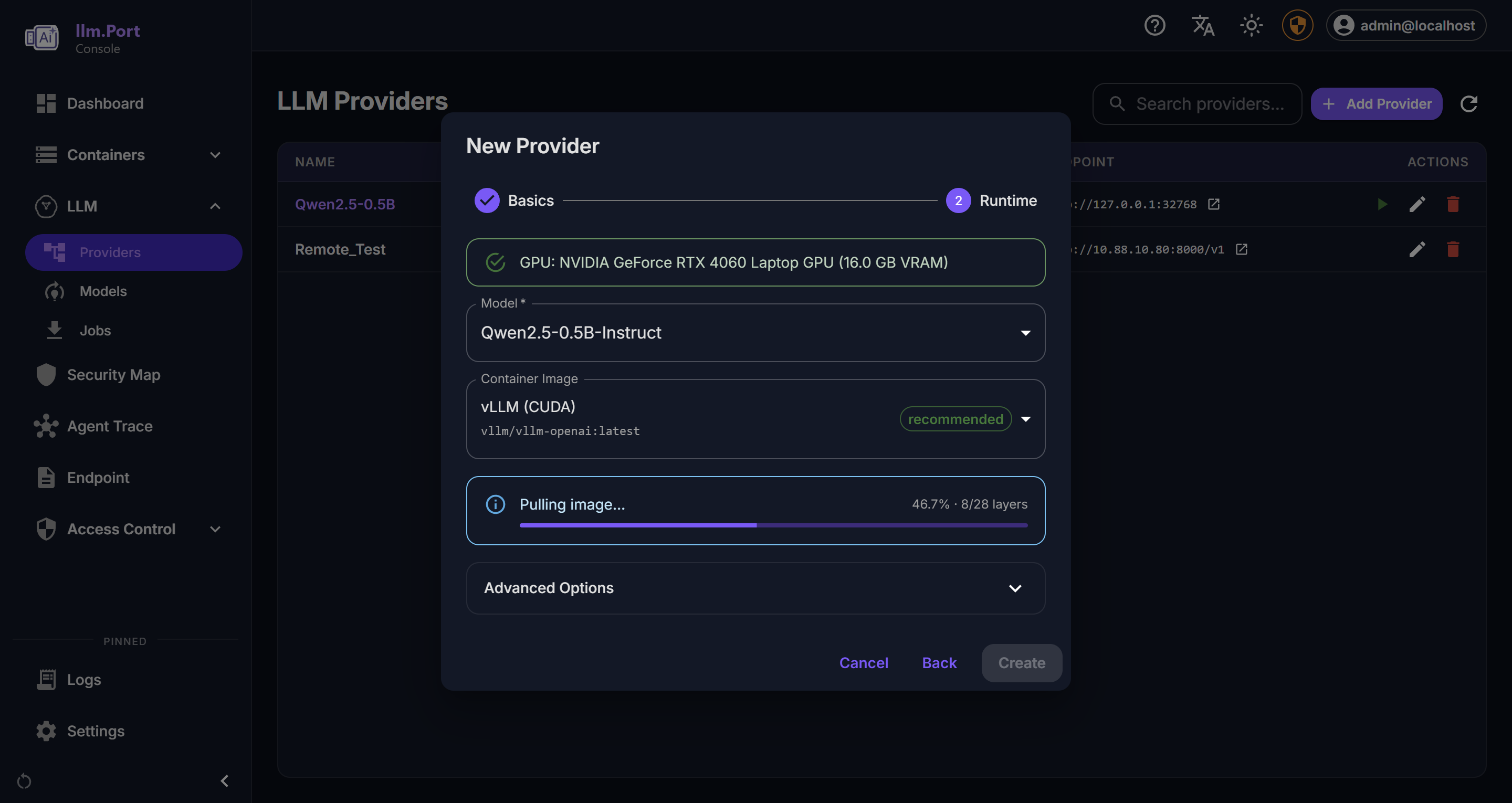 Local Runtime
Local Runtime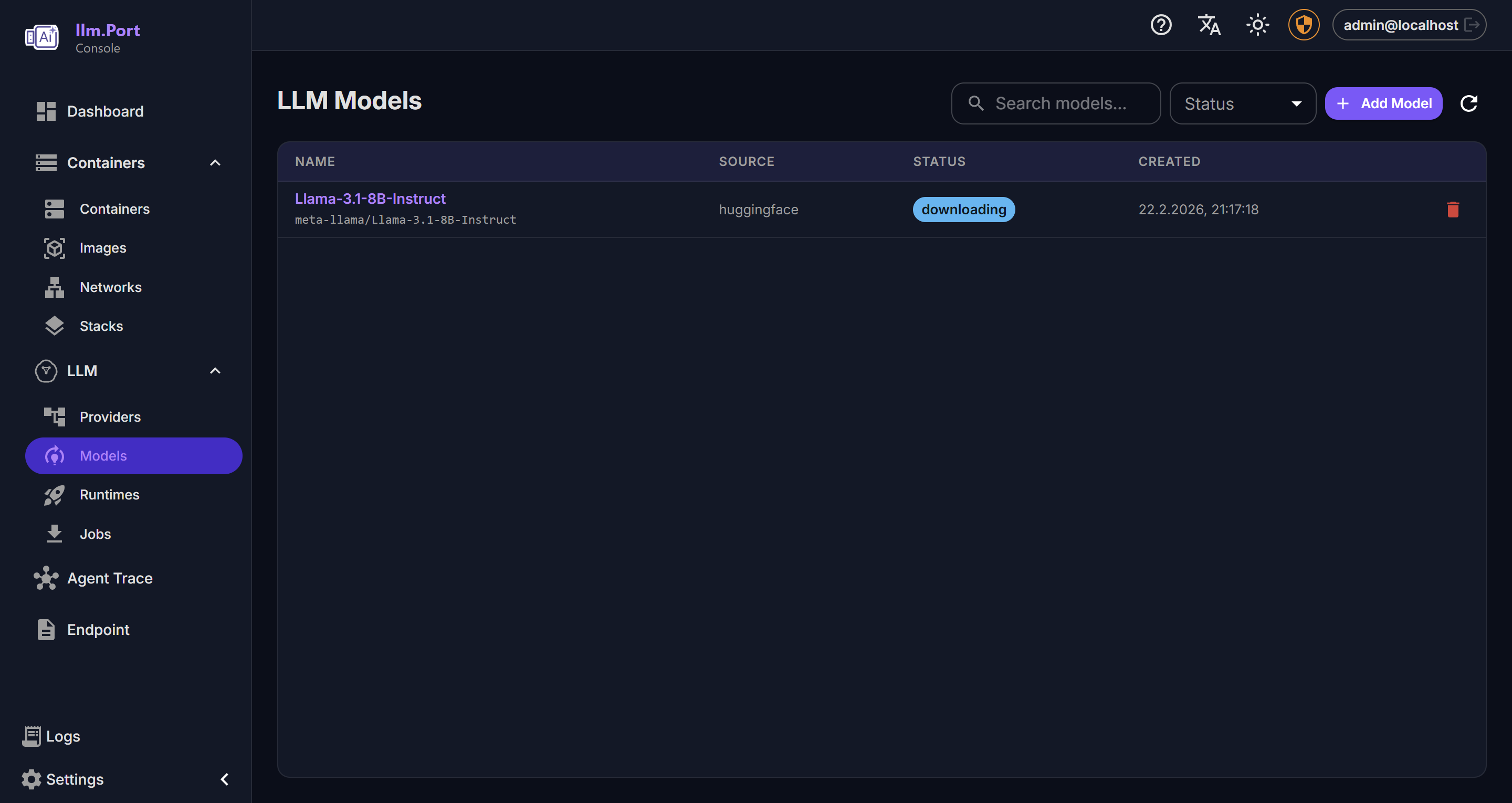 Models
Models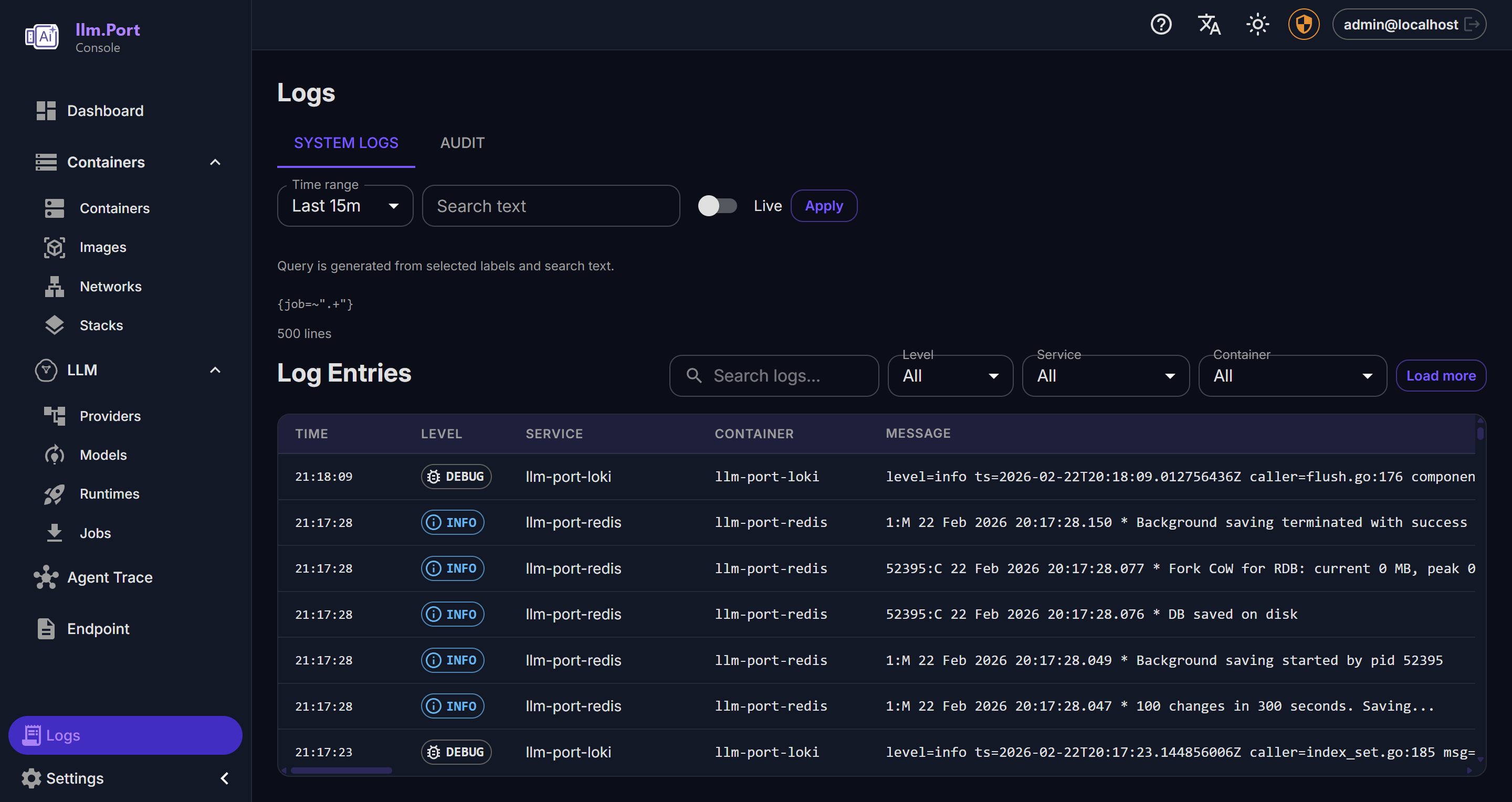 Logging
Logging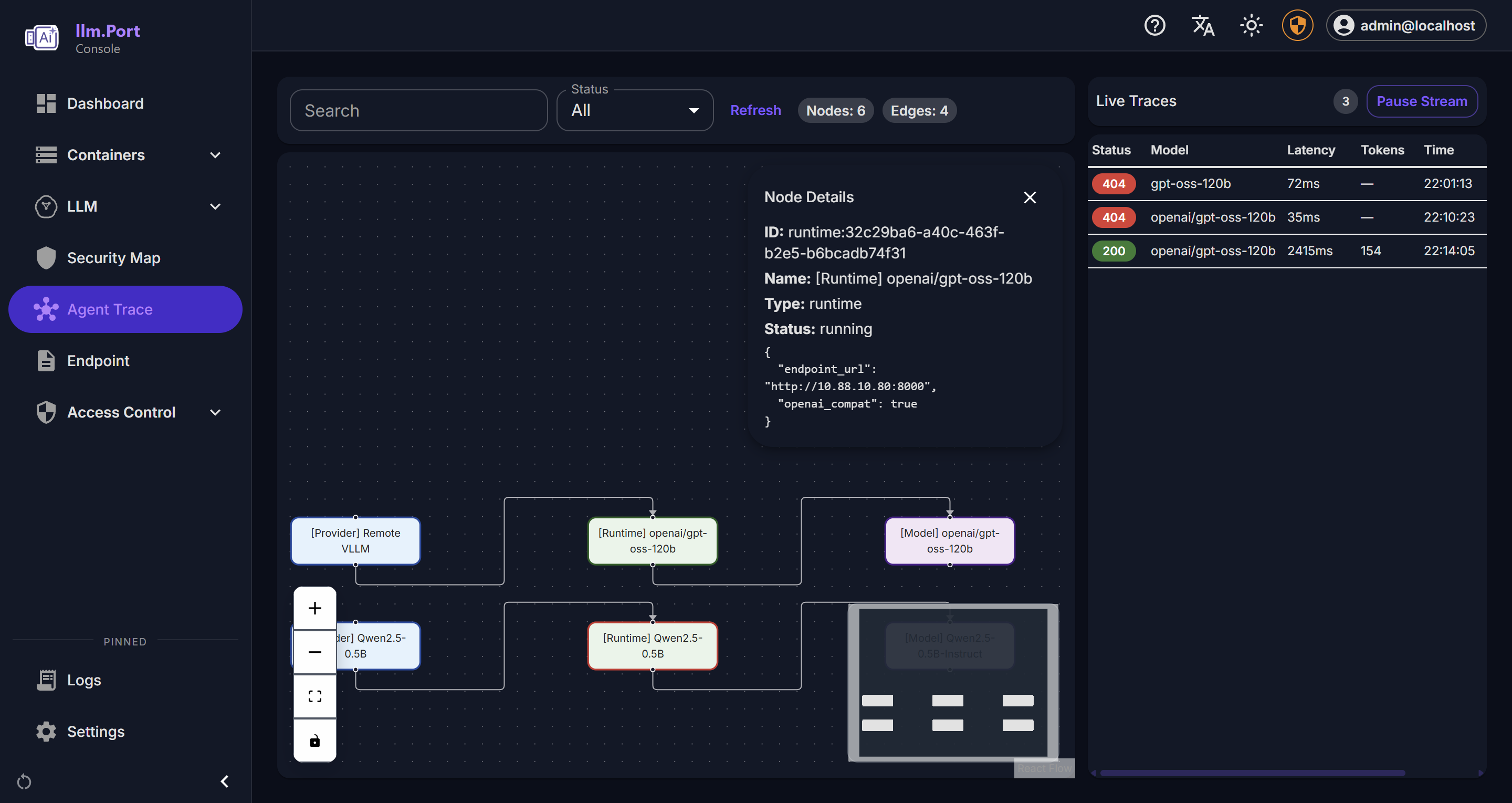 Trace Viewer
Trace Viewer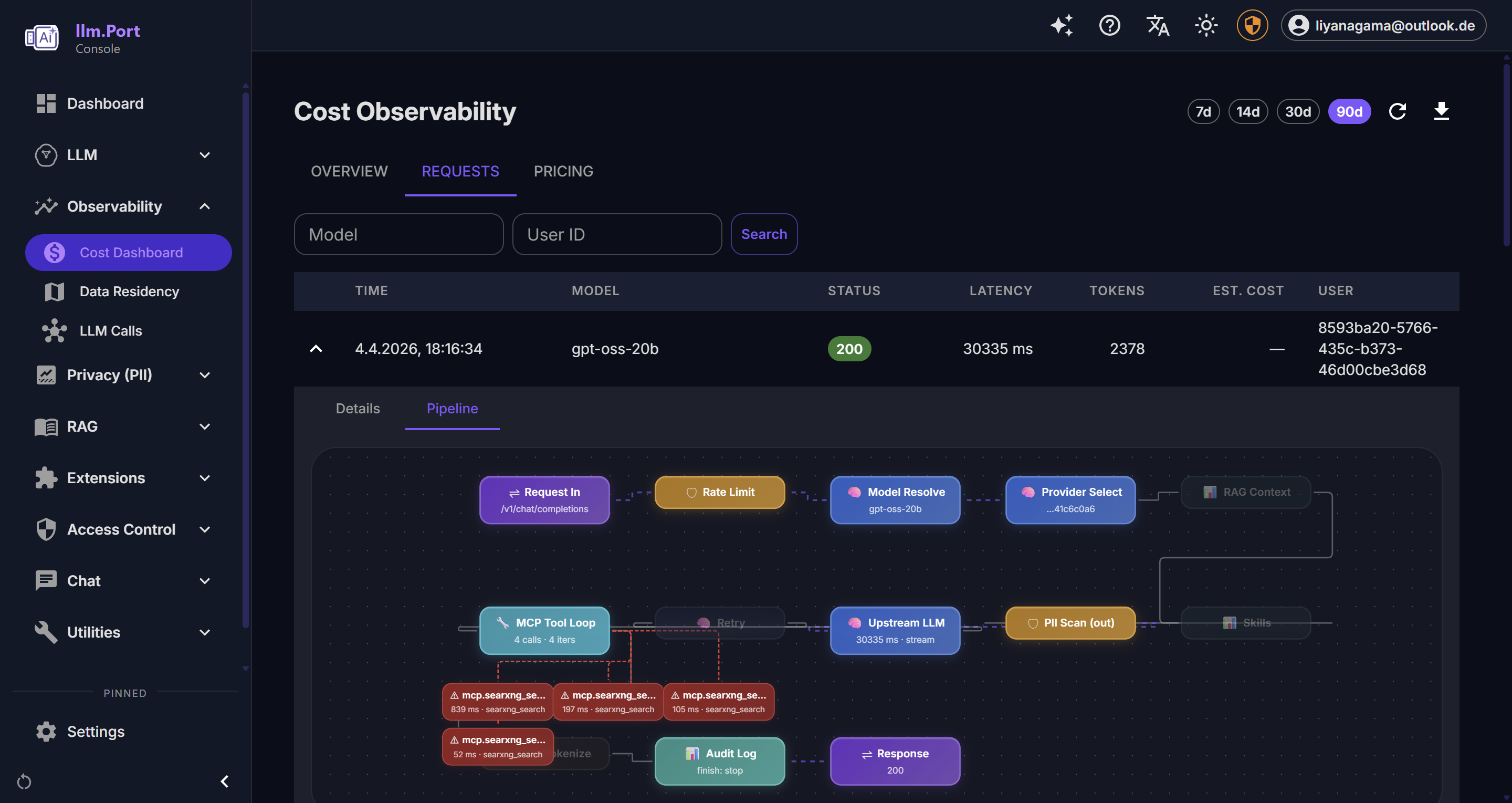 Cost & Request Trends
Cost & Request Trends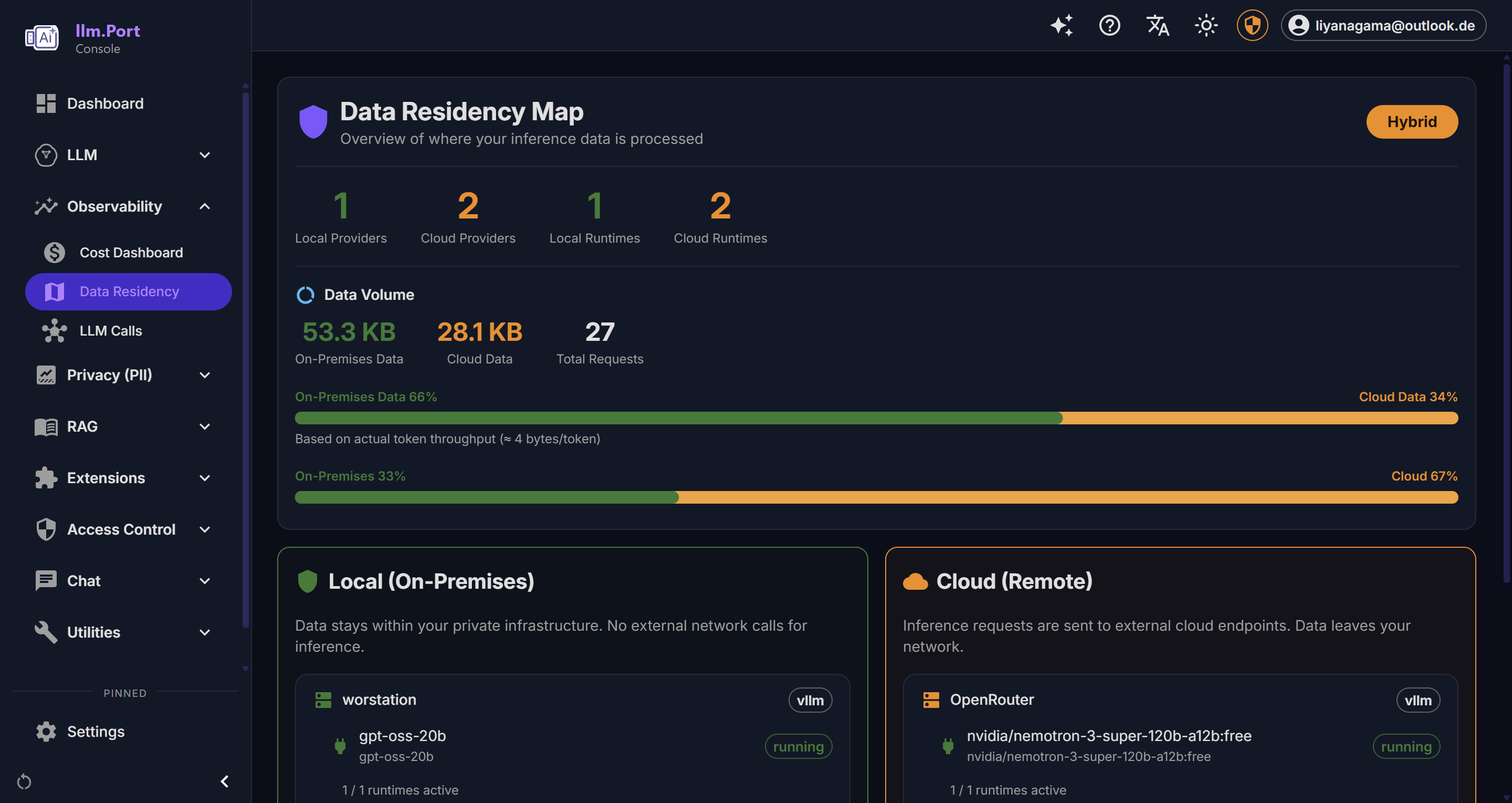 Security Overview
Security Overview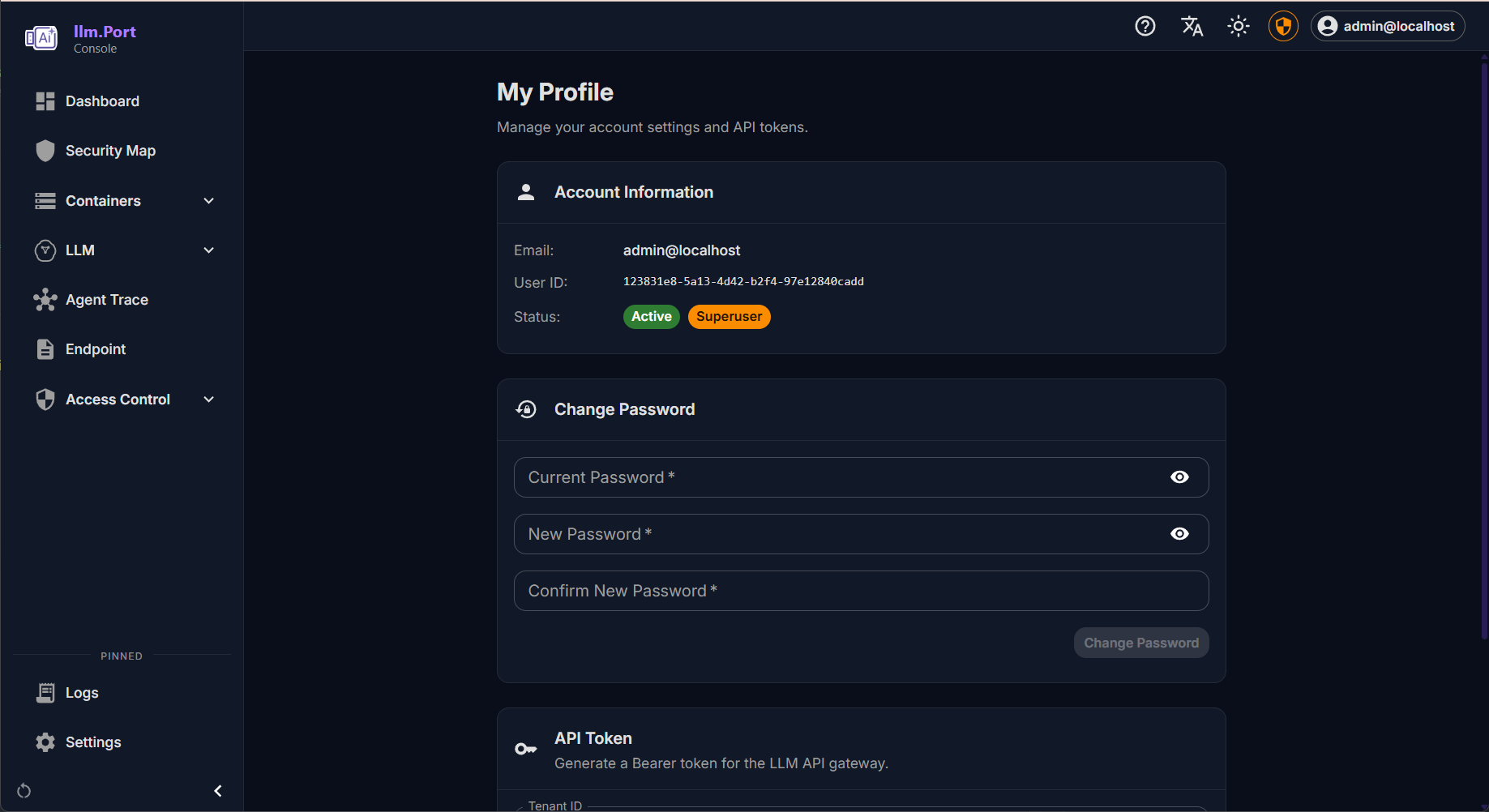 User Profile
User Profile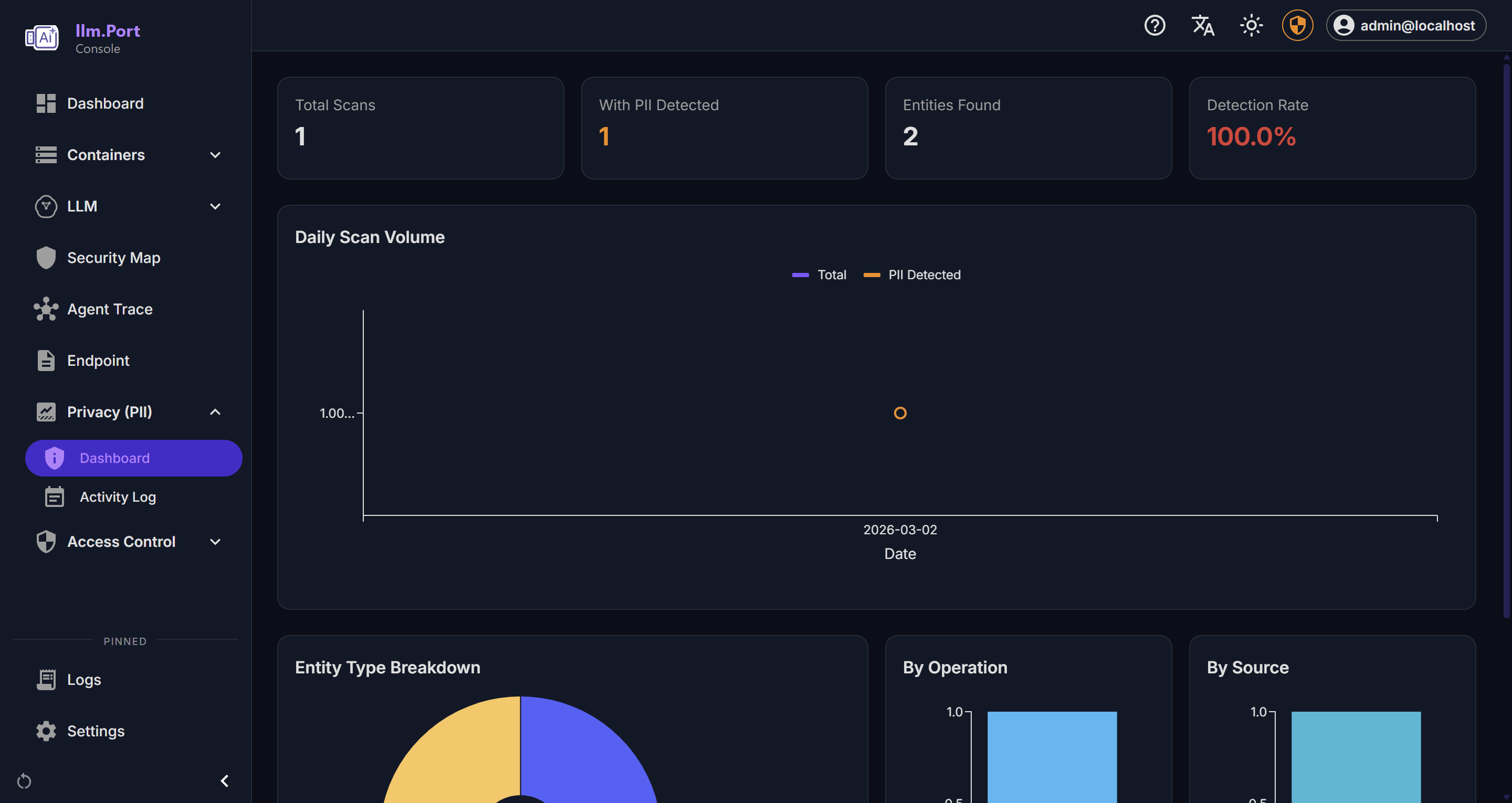 PII Detection
PII Detection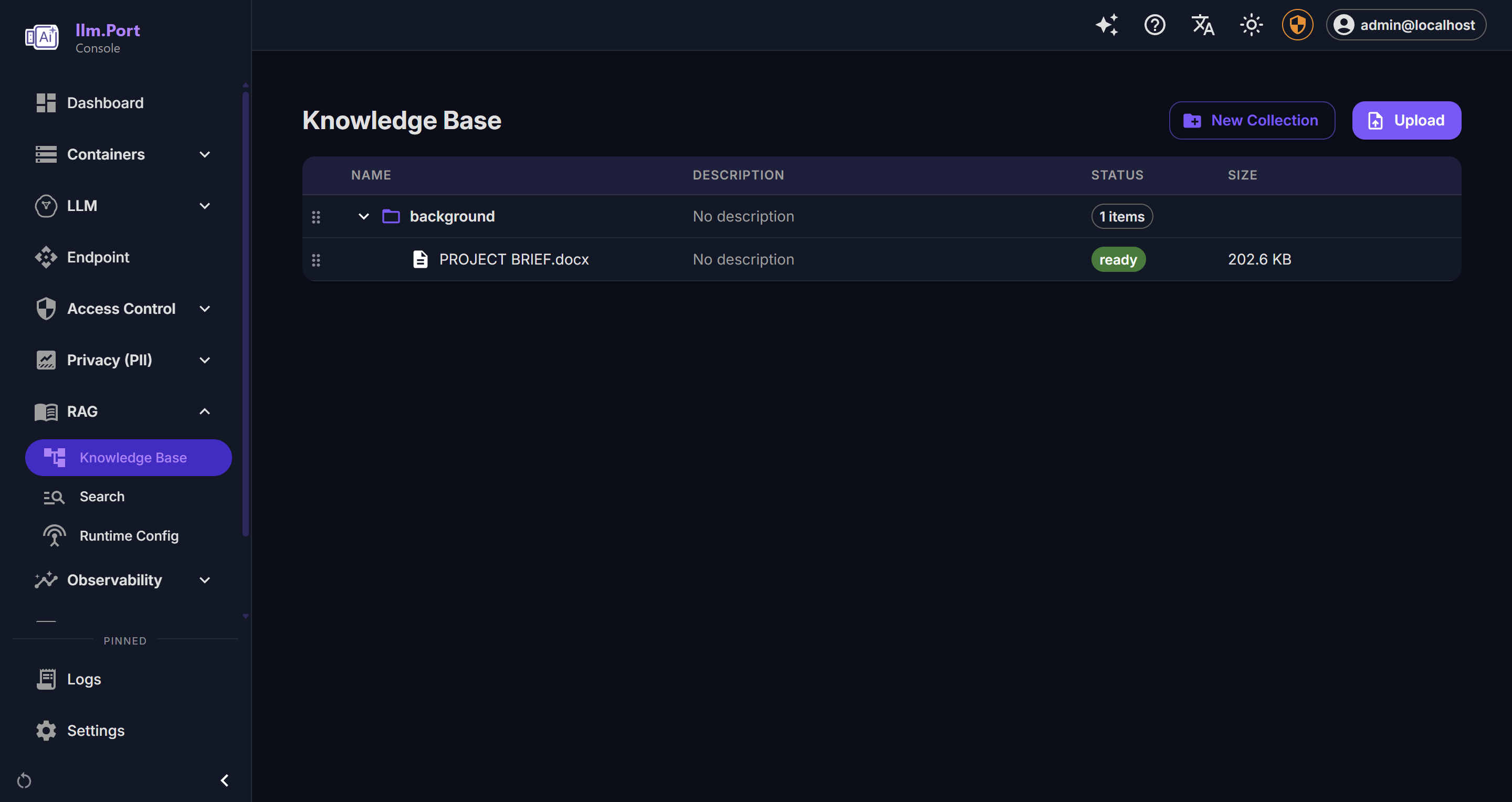 Knowledge Base
Knowledge Base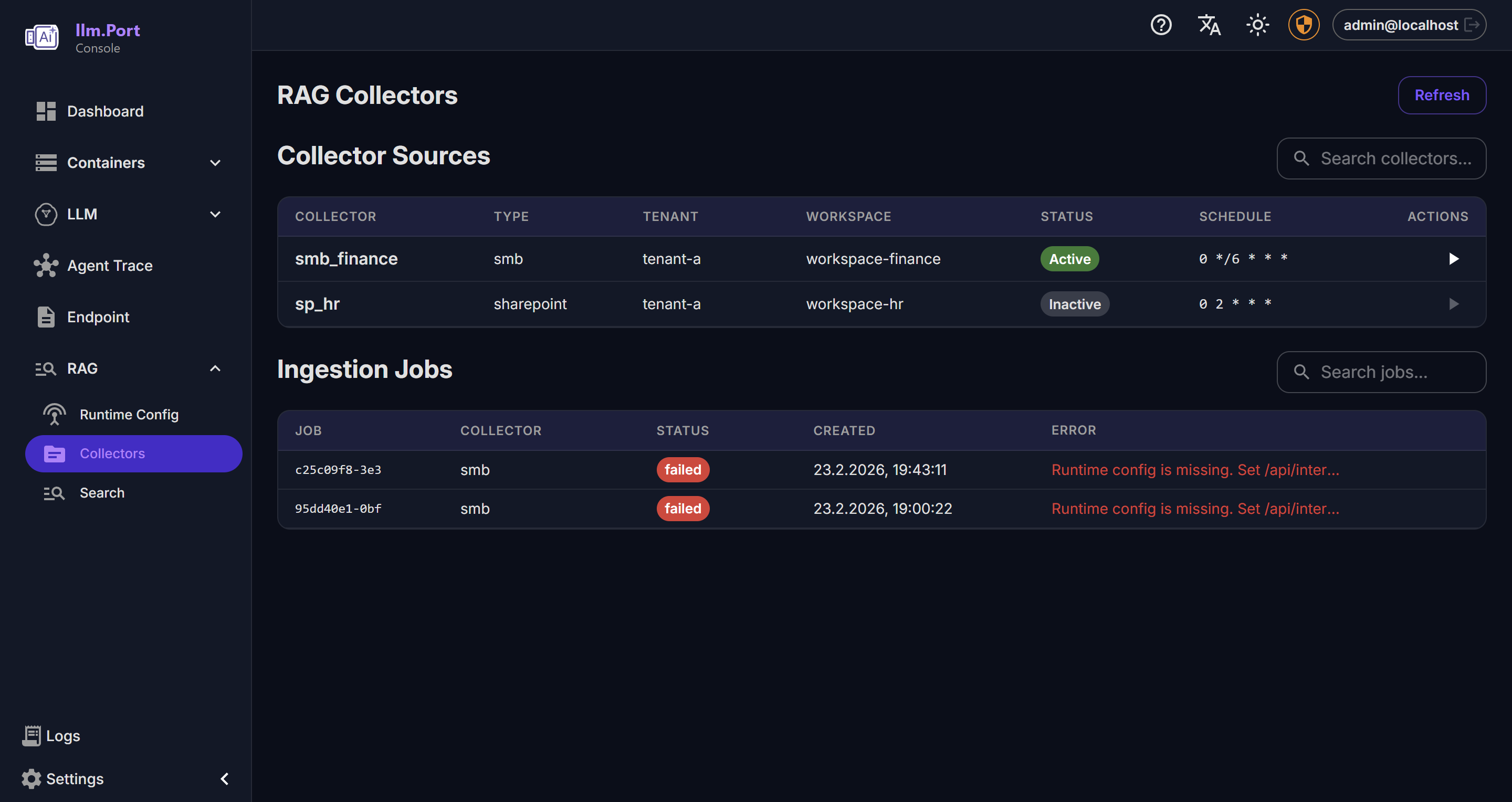 RAG Collectors
RAG Collectors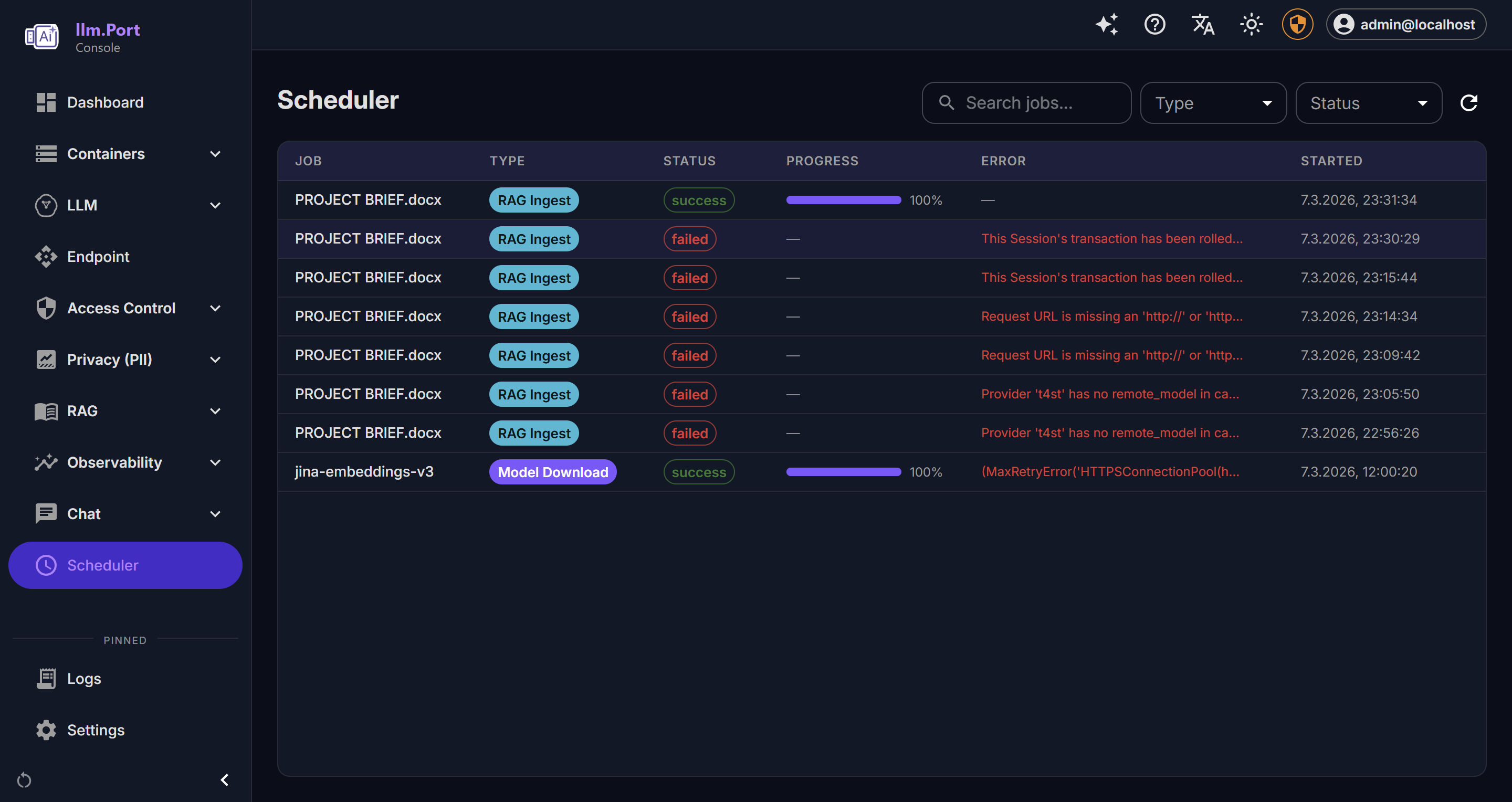 Scheduled Publishing
Scheduled Publishing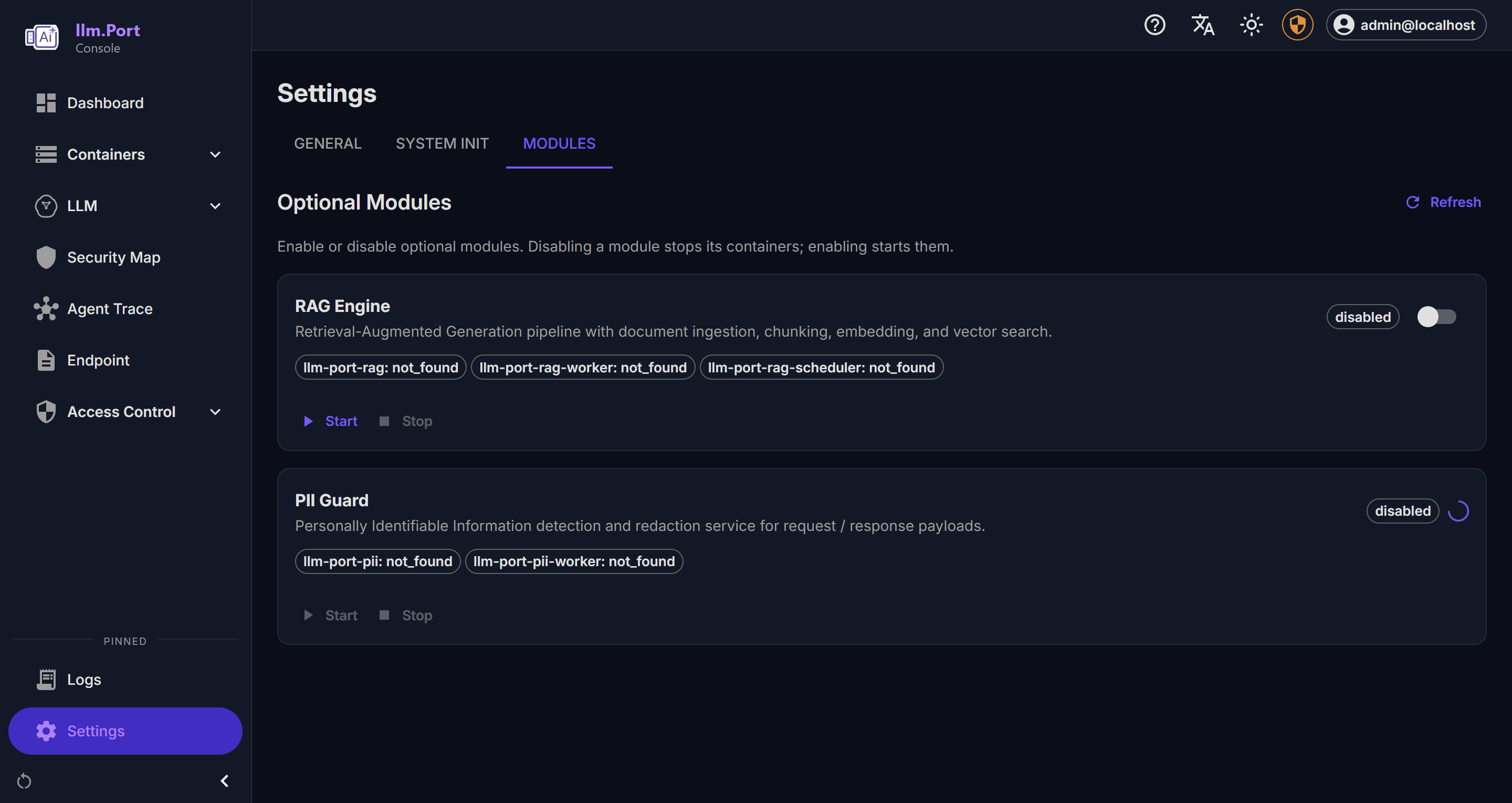 Modules
Modules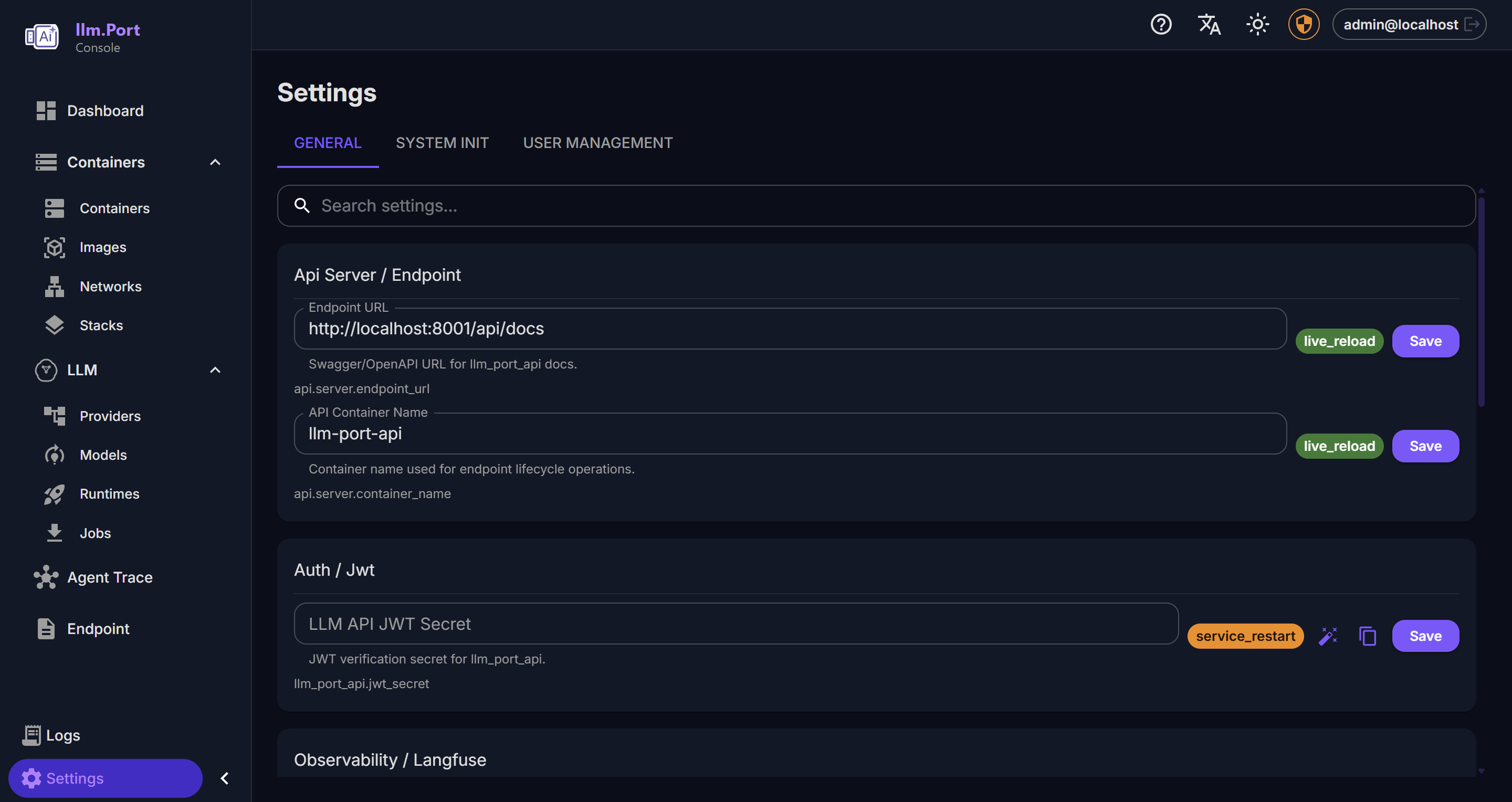 Settings
Settings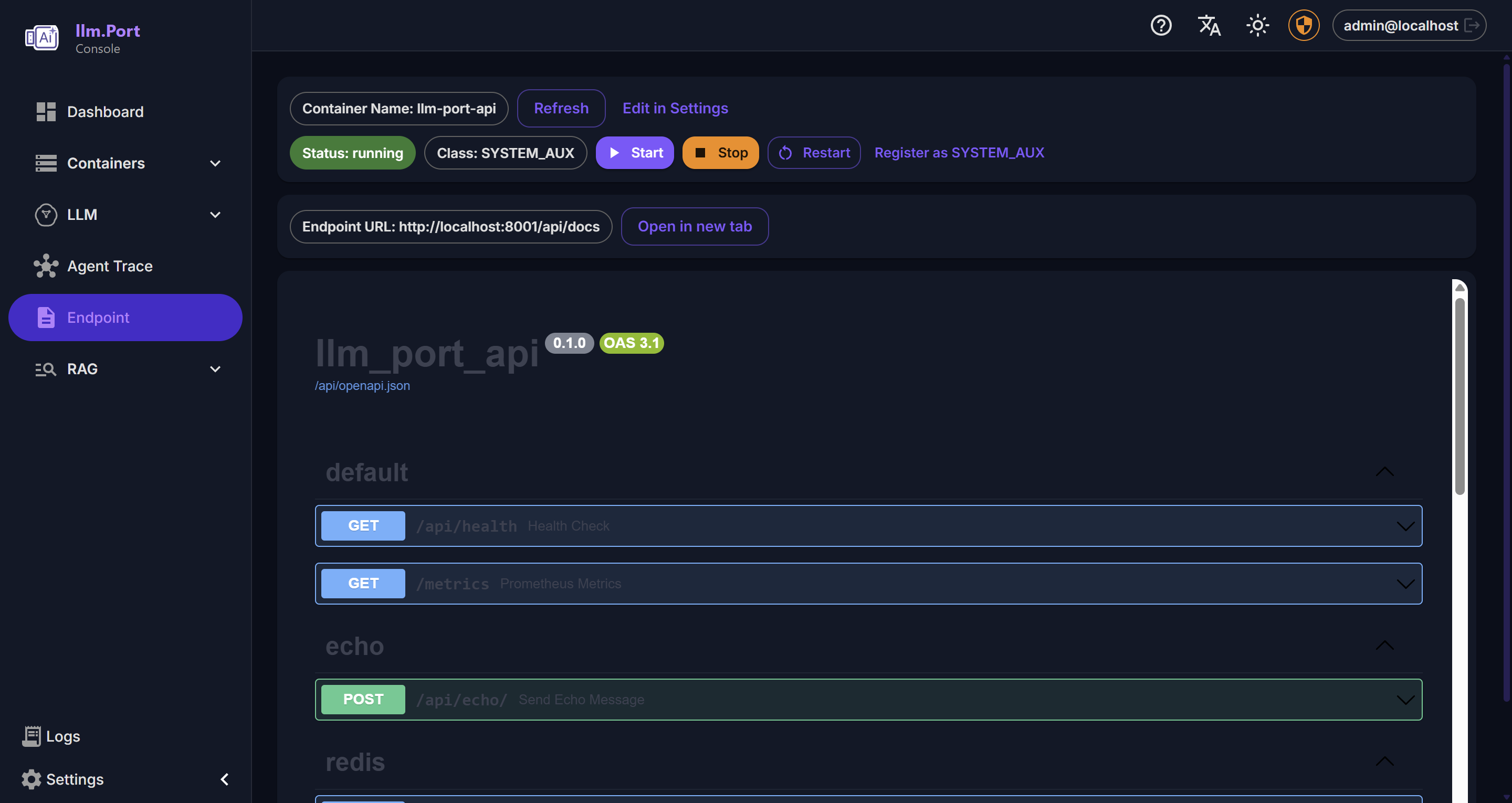 API Playground
API PlaygroundEnterprise features available for teams that need SSO, advanced PII tokenization, and governance. Get in touch →