llm.Port
Self-hosted all-in-one LLM platform
Enruta, asegura y observa el tráfico entre runtimes LLM locales y proveedores remotos — brindando a los equipos un único lugar para gestionar servicios LLM de extremo a extremo.
# Install the CLI
$ pip install llmport-cli
# Check prerequisites & deploy
$ llmport doctor
$ llmport deploy
# Enable optional modules
$ llmport module enable pii
$ llmport module enable ragDisponible en English, Deutsch, Español, 中文
Cómo funciona
API Gateway
Endpoint /v1/* compatible con OpenAI. Enruta a vLLM, llama.cpp, Ollama, TGI y proveedores remotos (OpenAI, Azure, …). Streaming SSE, resolución de modelos basada en alias, reintentos y limitación de tasa.
Capa PII
Integración con Microsoft Presidio para detección y redacción en tiempo real. Políticas por inquilino con tipos de entidad configurables y modos fail-safe.
Orquestación de GPU
Detección automática de GPUs NVIDIA (CUDA), AMD (ROCm) e Intel. Inicia contenedores vLLM con la imagen correcta (CUDA / ROCm / Legacy). Montaje de caché HuggingFace para carga rápida de modelos.
Almacenamiento
PostgreSQL con pgvector para búsqueda vectorial (RAG). Redis para limitación de tasa, caché de sesiones y leasing distribuido. MinIO para almacenamiento de documentos compatible con S3.
Observabilidad
Langfuse para trazado LLM con modos de privacidad. Grafana + Loki + Alloy para registro centralizado. OpenTelemetry + Jaeger para trazado distribuido. Métricas Prometheus.
Plano de Control
Backend FastAPI para RBAC, configuraciones, orquestación Docker, ciclo de vida de módulos, infraestructura de agentes y gestión de stacks Compose con seguimiento de revisiones.
Funcionalidades
Gateway y Enrutamiento
Endpoint API compatible con OpenAI (/v1/*) que enruta a runtimes locales (vLLM, llama.cpp, Ollama, TGI) y proveedores remotos (OpenAI, Azure, …). Resolución de modelos basada en alias, streaming SSE con extracción de TTFT y reintentos automáticos.
Seguridad y PII
RBAC completo con autenticación JWT, OAuth / SSO / OIDC, limitación de tasa con Redis, leasing de concurrencia y secretos de BD cifrados con Fernet. Detección de PII basada en Presidio con políticas por inquilino, tipos de entidad configurables y modos fail-safe.
Observabilidad
Trazado Langfuse con modos de privacidad, registro centralizado Loki + Alloy, trazado distribuido OpenTelemetry + Jaeger, y un panel con embeds de Grafana. Cada solicitud al gateway y acción administrativa queda en el registro de auditoría.
Pipeline RAG
Recuperación multi-inquilino con búsqueda vectorial, por palabras clave e híbrida. Árbol de contenedores virtual con flujos de borrador/publicación, cargas presignadas a MinIO, plugins de recolección y procesamiento asíncrono vía Taskiq + RabbitMQ.
Consola de Operaciones
Gestión completa del ciclo de vida de contenedores, pulls de imágenes con progreso SSE, deploy/rollback de stacks Compose con revisiones y registro de auditoría. Detección automática de GPU multi-fabricante (NVIDIA, AMD, Intel, Apple Metal).
Consola de Chat
Interfaz de chat integrada con streaming SSE, gestión de sesiones con arrastrar y soltar, reintento de errores, temas oscuro/claro y seguimiento de uso por modelo. Compatible con todos los modelos conectados al gateway.
Cómo se compara llm.port
| Funcionalidad | llm.port | LiteLLM | Ollama |
|---|---|---|---|
| Gateway compatible con OpenAI | ✅ | ✅ | ✅ |
| UI de administración | ✅ Built-in | 💰 Paid | ❌ |
| Capa de redacción PII | ✅ Native | ❌ | ❌ |
| Pipeline RAG | ✅ Built-in | ❌ | ❌ |
| Chat Console with Memory | ✅ | ❌ | ❌ |
| Detección automática de GPU | ✅ Auto-detect | ❌ | ✅ |
| Langfuse Tracing | ✅ Embedded | 🔌 Plugin | ❌ |
| Grafana + Loki Logging | ✅ Pre-configured | ❌ | ❌ |
| RBAC / multi-inquilino | ✅ | 💰 Partial | ❌ |
| i18n (4 idiomas) | ✅ | ❌ | ❌ |
| Herramientas CLI | ✅ llmport deploy | ❌ | ❌ |
| License | Apache 2.0 | MIT + Paid | MIT |
¿Por qué llm.port?
IA soberana por defecto — mantén los datos on-prem cuando sea necesario, usa proveedores remotos cuando esté permitido, sin cambiar tus aplicaciones ni perder gobernanza y observabilidad. Una plataforma reemplaza un parche de proxies, dashboards y scripts.
GTC 2026 Infraestructura de Inferencia para la Empresa
Los equipos que despliegan los modelos y arquitecturas de aceleradores presentados en GTC 2026 necesitan más que un runtime — necesitan un gateway seguro. llm.port proporciona la capa de producción que falta: un API gateway compatible con OpenAI con redacción PII integrada, RBAC y observabilidad completa — todo ejecutándose dentro de tu VPC privada. Ningún dato sale de tu perímetro.
- Gateway API seguro con limitación de tasa, reintentos y enrutamiento de modelos basado en alias
- Redacción PII antes del ingreso y egreso — basado en Microsoft Presidio
- Detección automática de GPU multi-fabricante (NVIDIA CUDA, AMD ROCm, Intel) con selección automática de imagen vLLM
- Observabilidad empresarial: trazado LLM Langfuse, dashboards Grafana y OpenTelemetry
- Despliegue soberano y aislado — sin dependencia de nube externa
Hoja de ruta
OCR avanzado (Docling)
IBM Docling para extracción enriquecida de documentos — tablas, imágenes, páginas. El servicio base existe; integración con pipeline RAG en progreso.
Servicio de autenticación (SSO / OIDC)
Servicio dedicado de autenticación para gestión de proveedores de identidad externos. Framework y perfil Compose definidos.
Servicio de correo
Servicio dedicado de envío de correos para restablecimiento de contraseñas, alertas de administración e invitaciones del sistema.
Módulos Enterprise Pro
Framework de licencias listo (Ed25519 JWT). Implementaciones Pro para PII, RAG y Gateway próximamente.
Más runtimes
TensorRT-LLM, SGLang y proveedores de API gestionados adicionales.
Control de costes detallado
Analíticas de uso por inquilino, modelo y usuario con límites de presupuesto y soporte de chargeback.
Capturas de pantalla
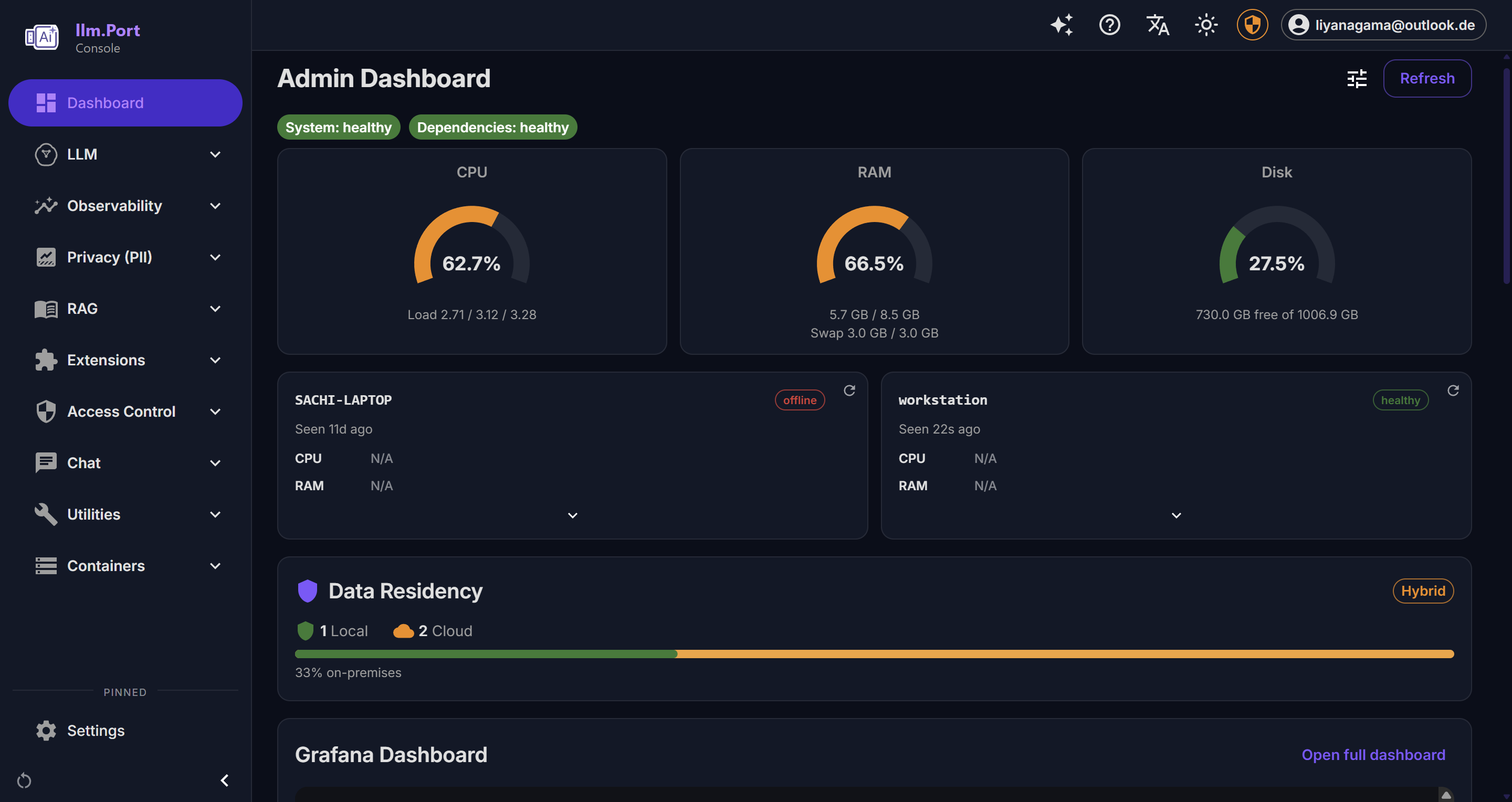 Dashboard
Dashboard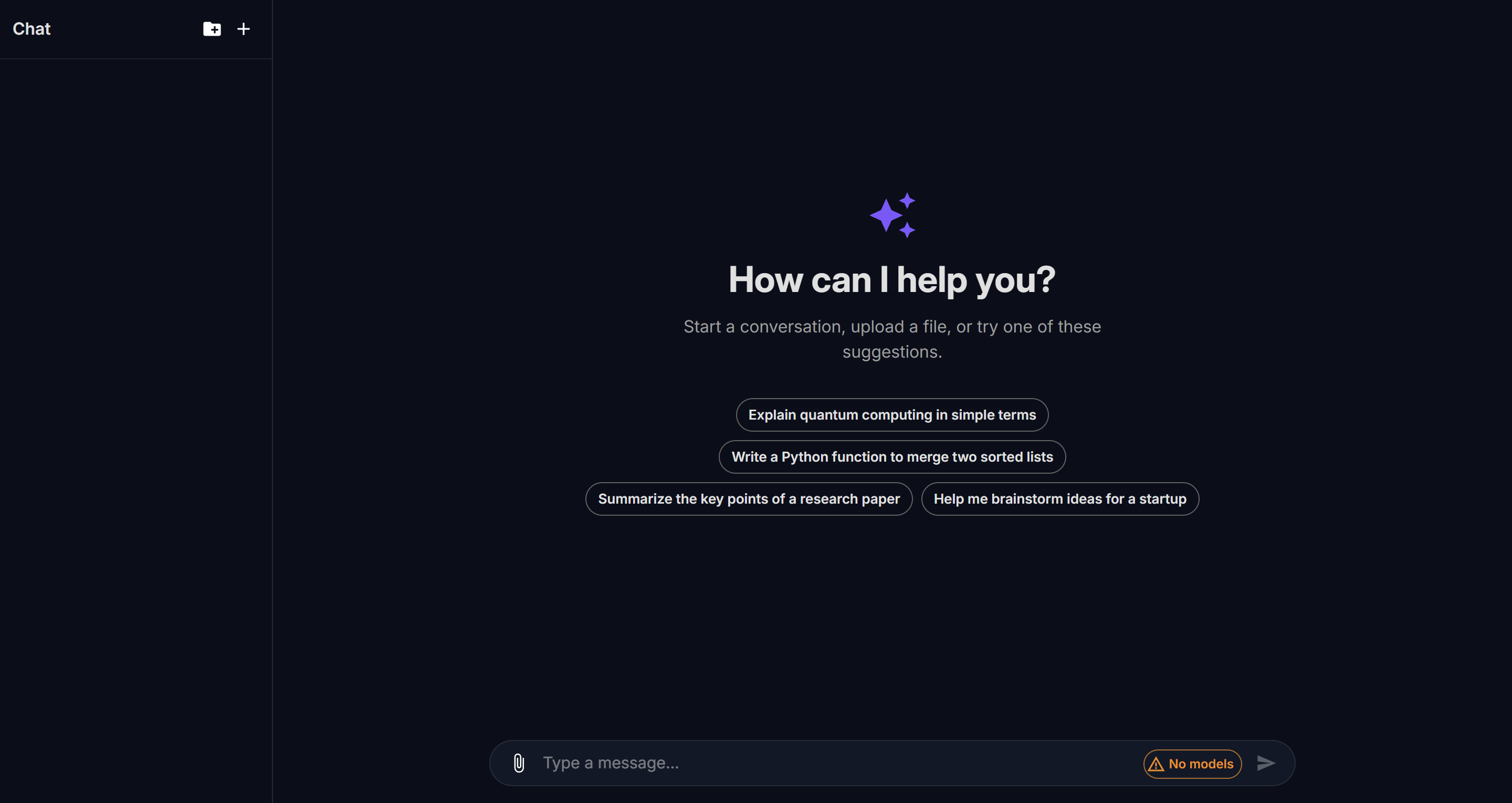 Chat Console
Chat Console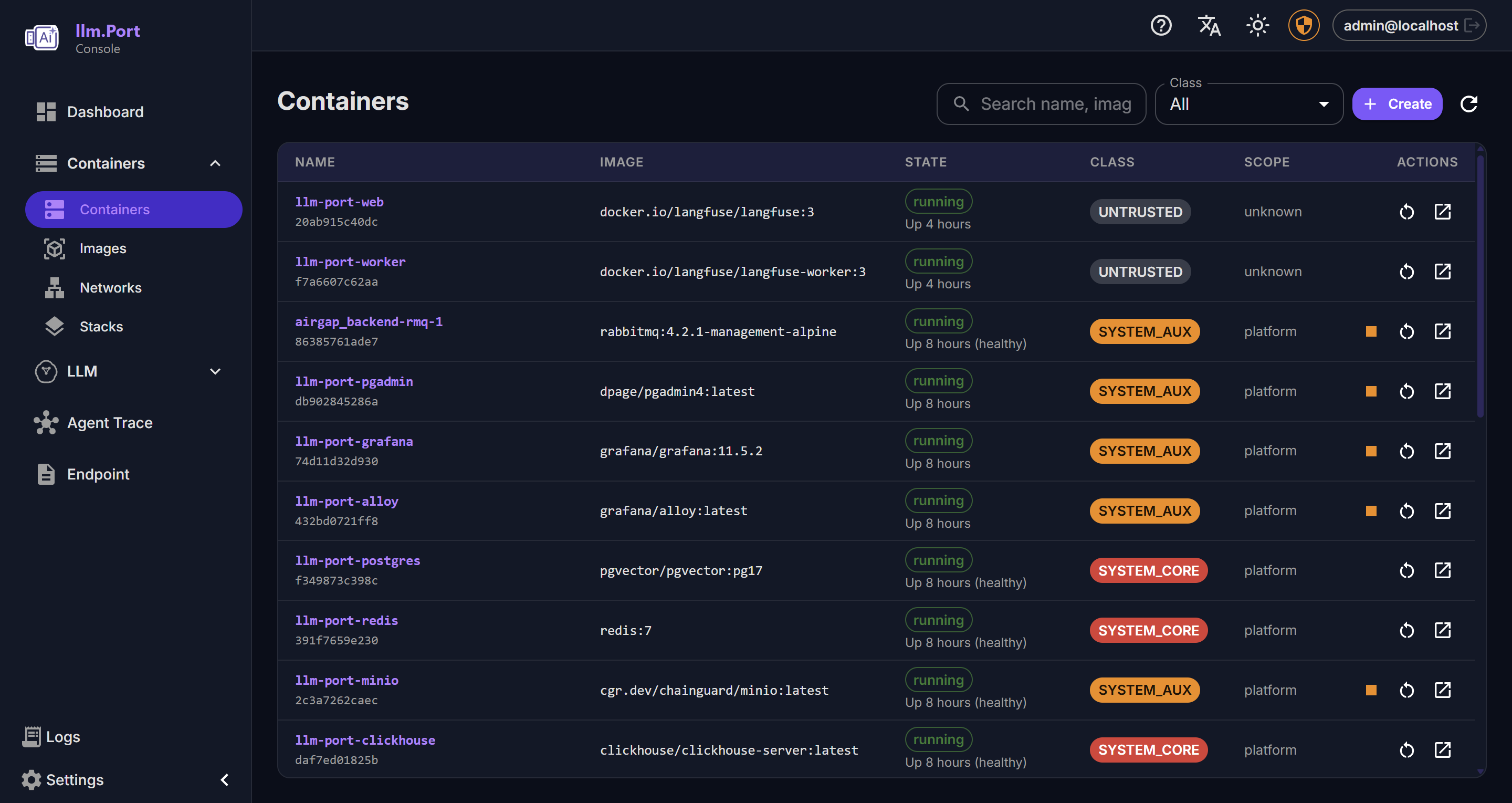 Container Management
Container Management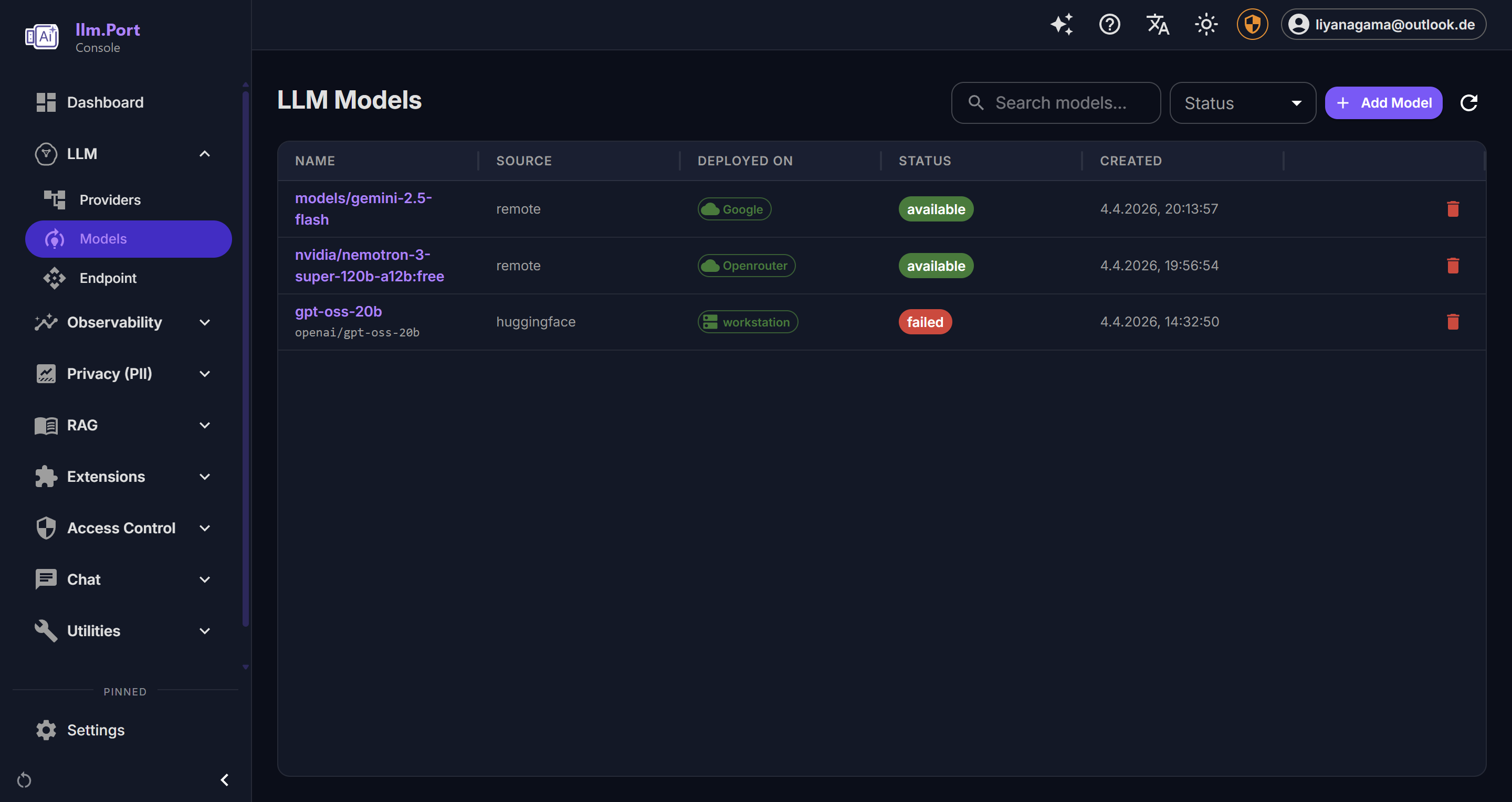 LLM Providers
LLM Providers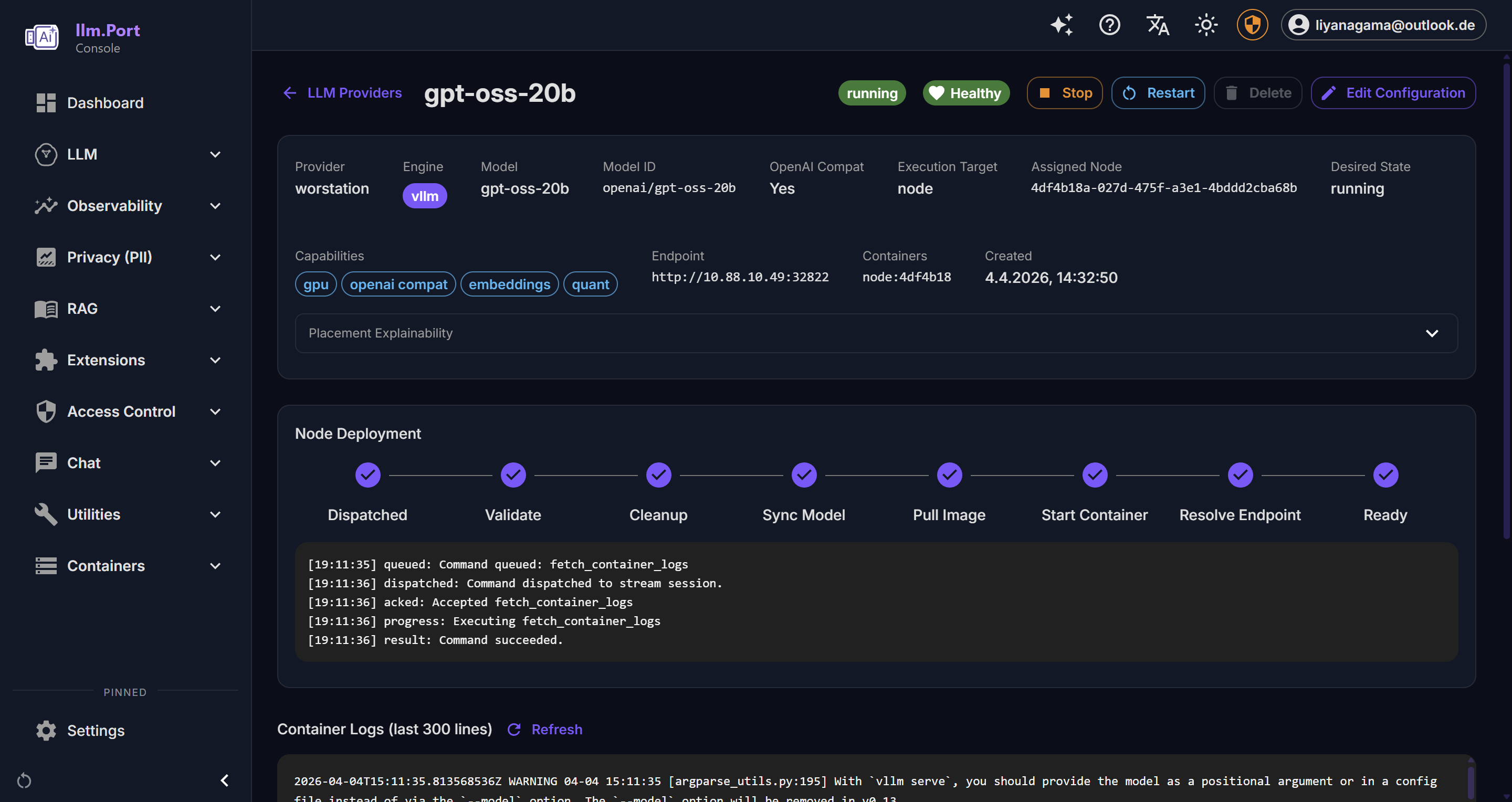 Provider Details
Provider Details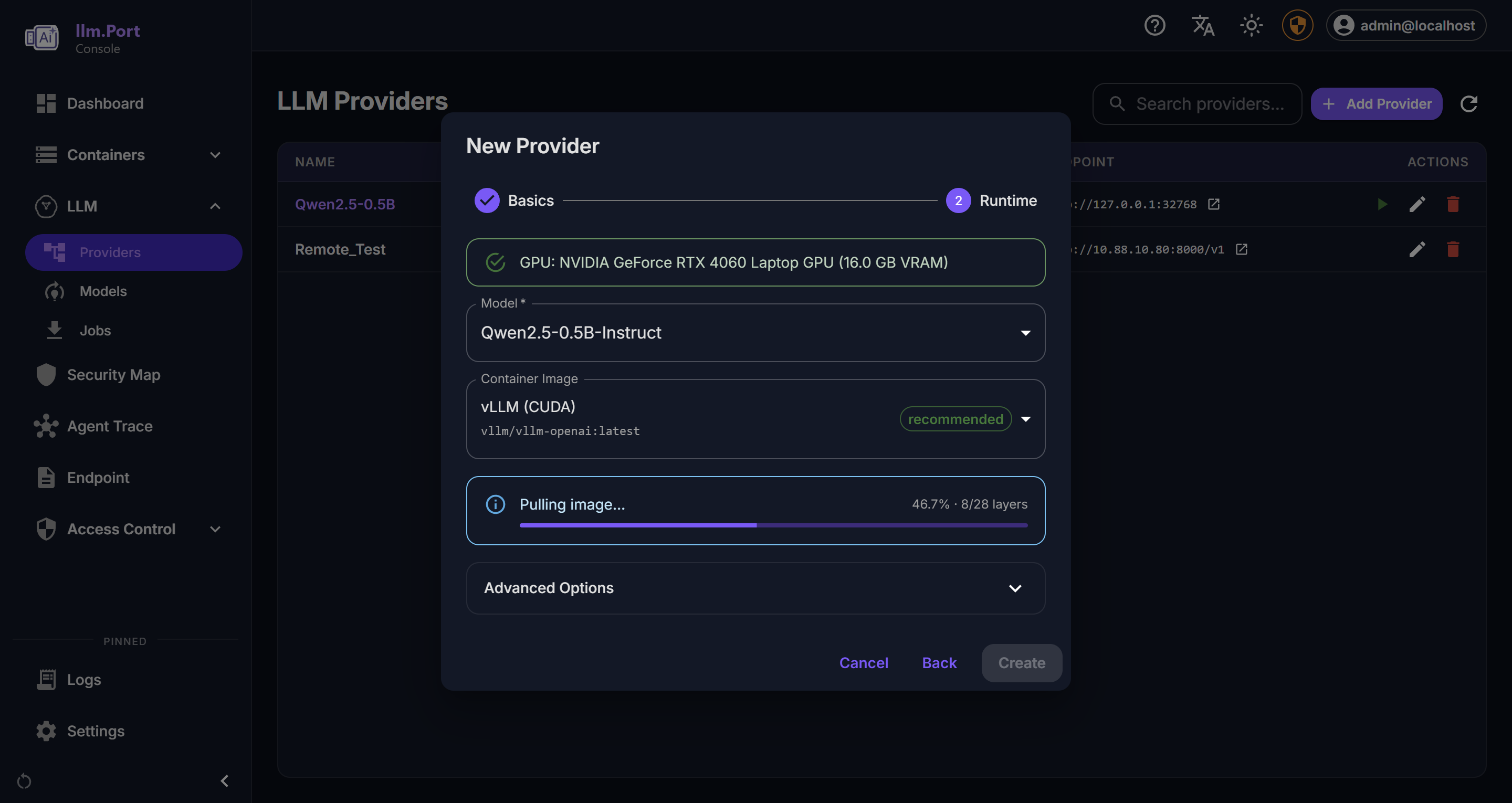 Local Runtime
Local Runtime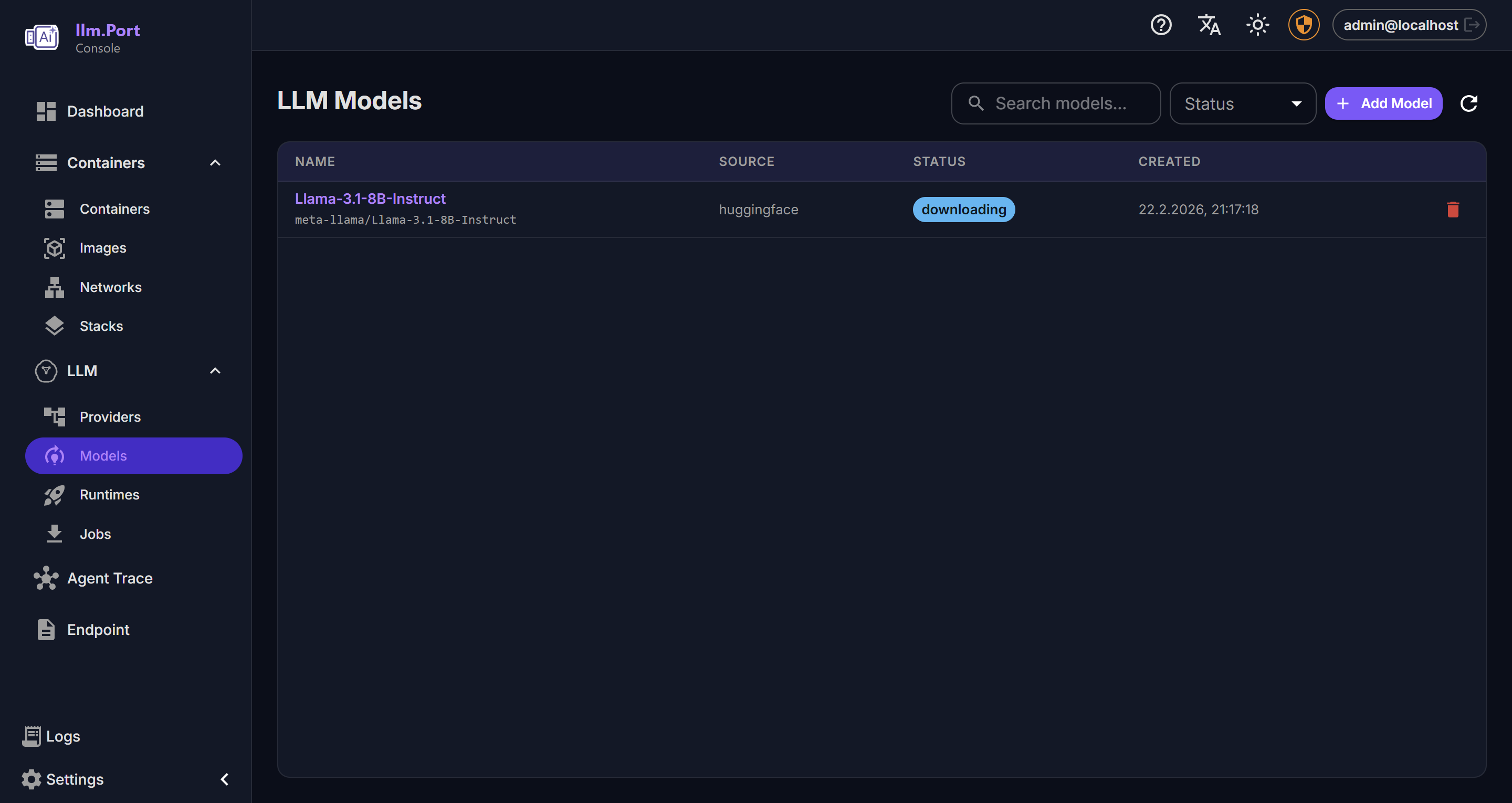 Models
Models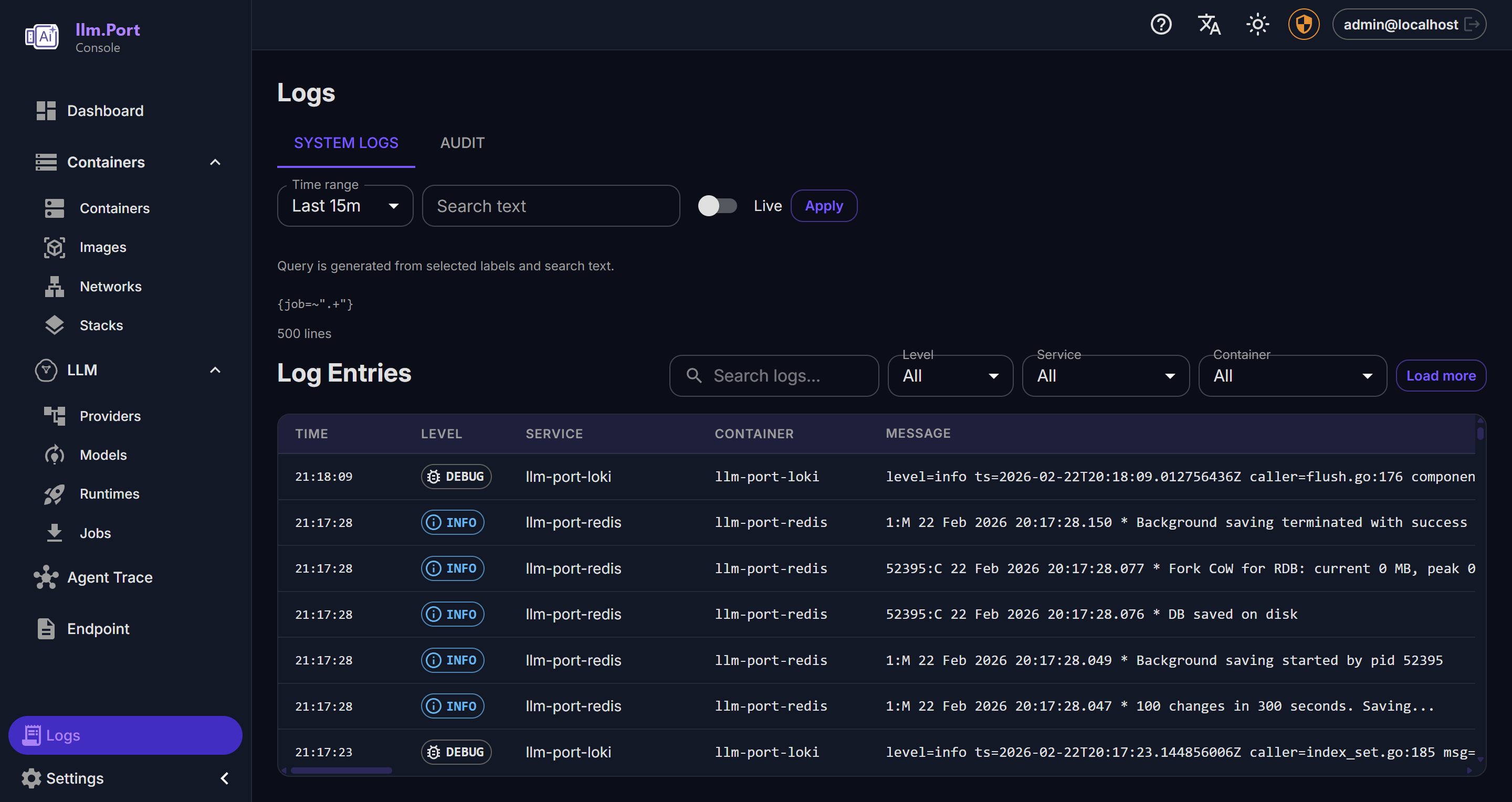 Logging
Logging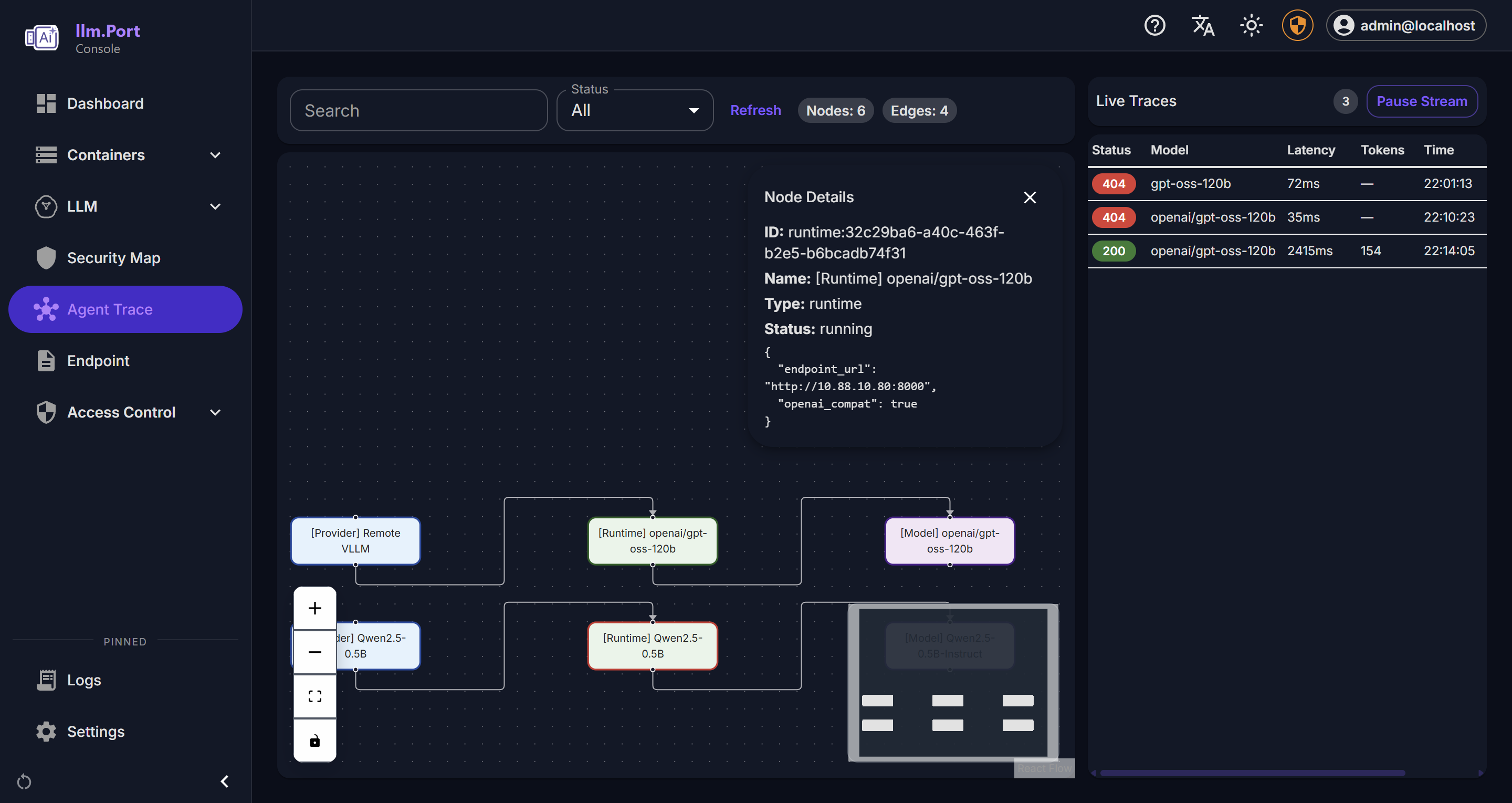 Trace Viewer
Trace Viewer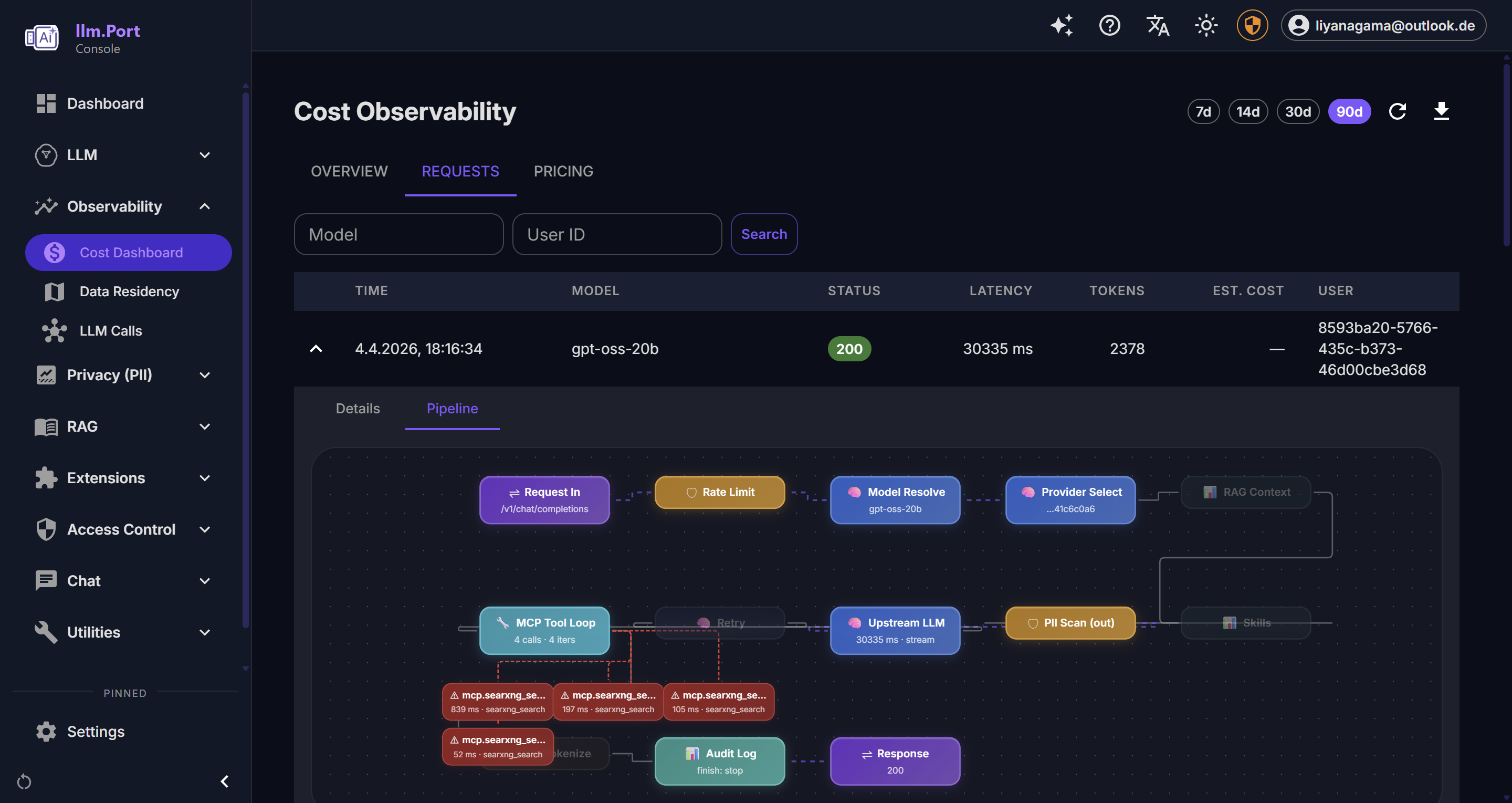 Cost & Request Trends
Cost & Request Trends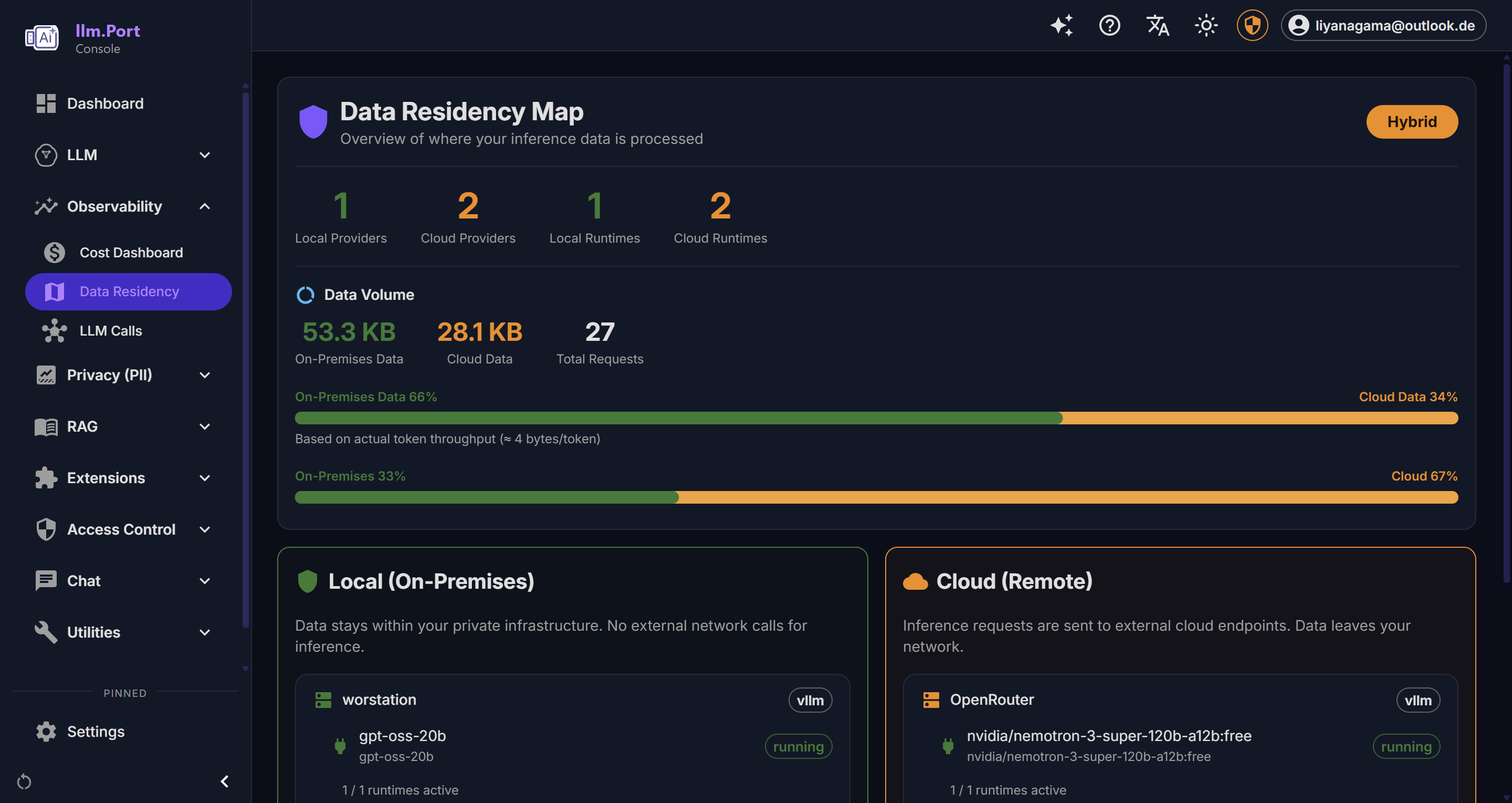 Security Overview
Security Overview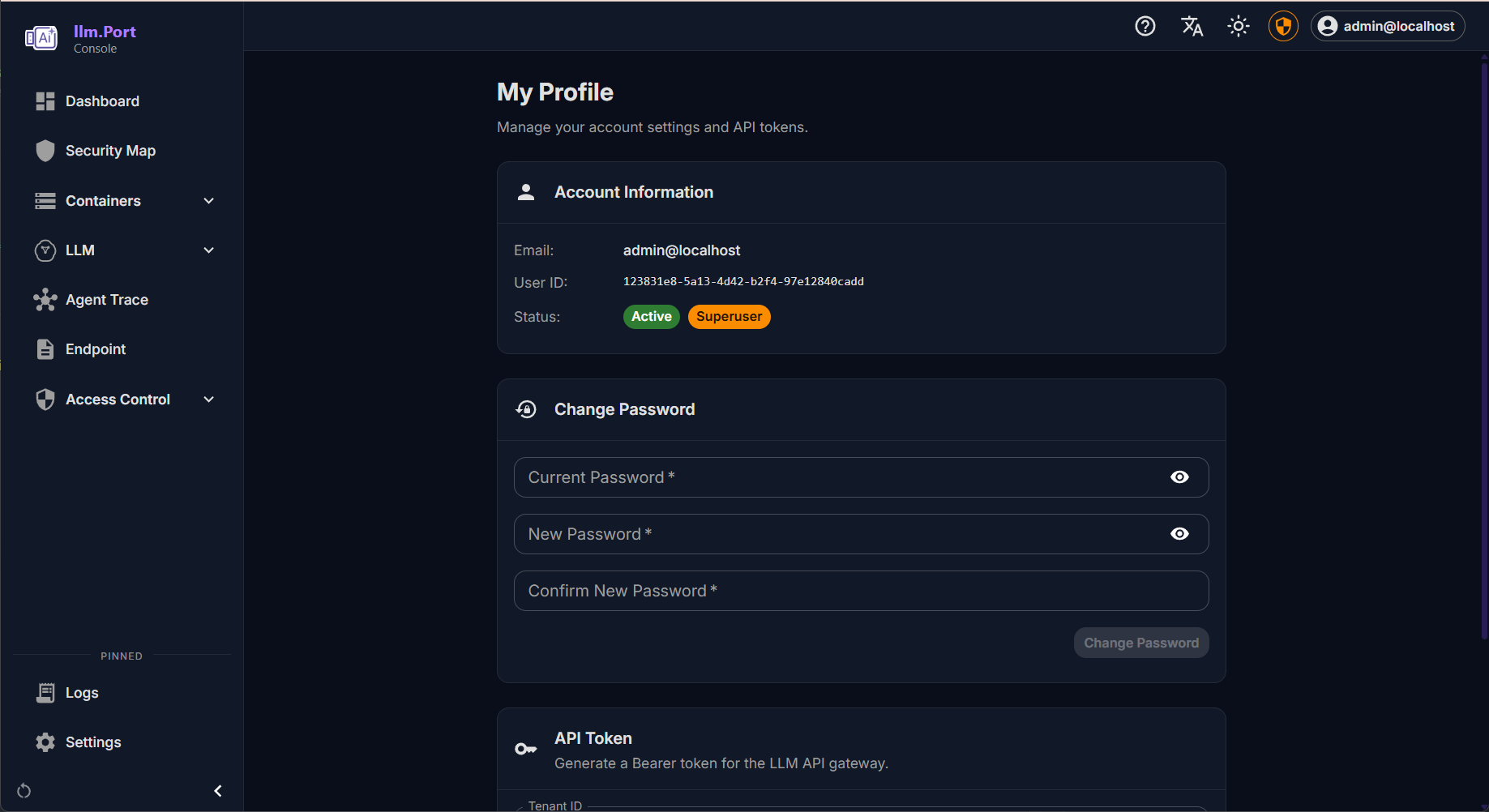 User Profile
User Profile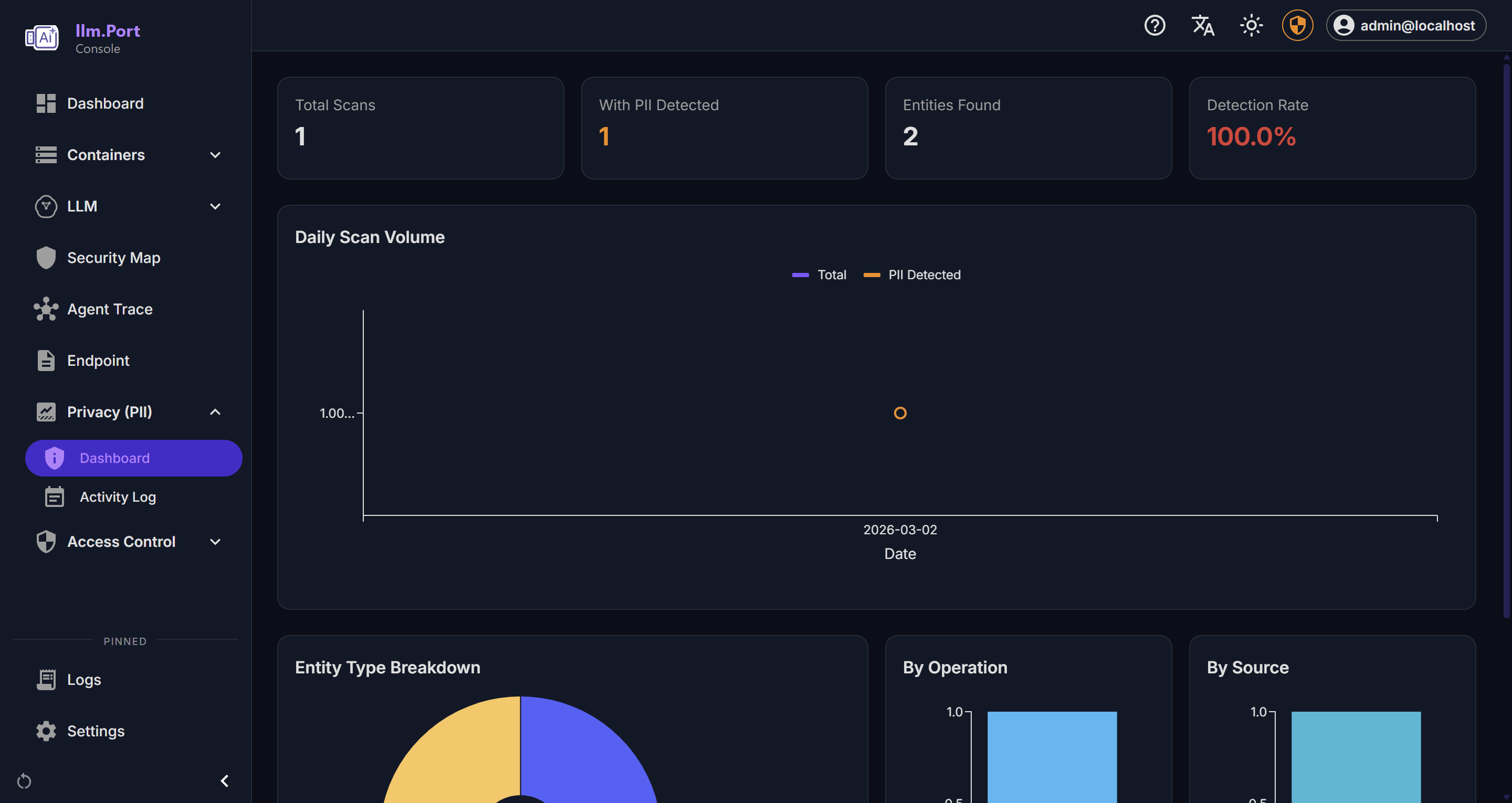 PII Detection
PII Detection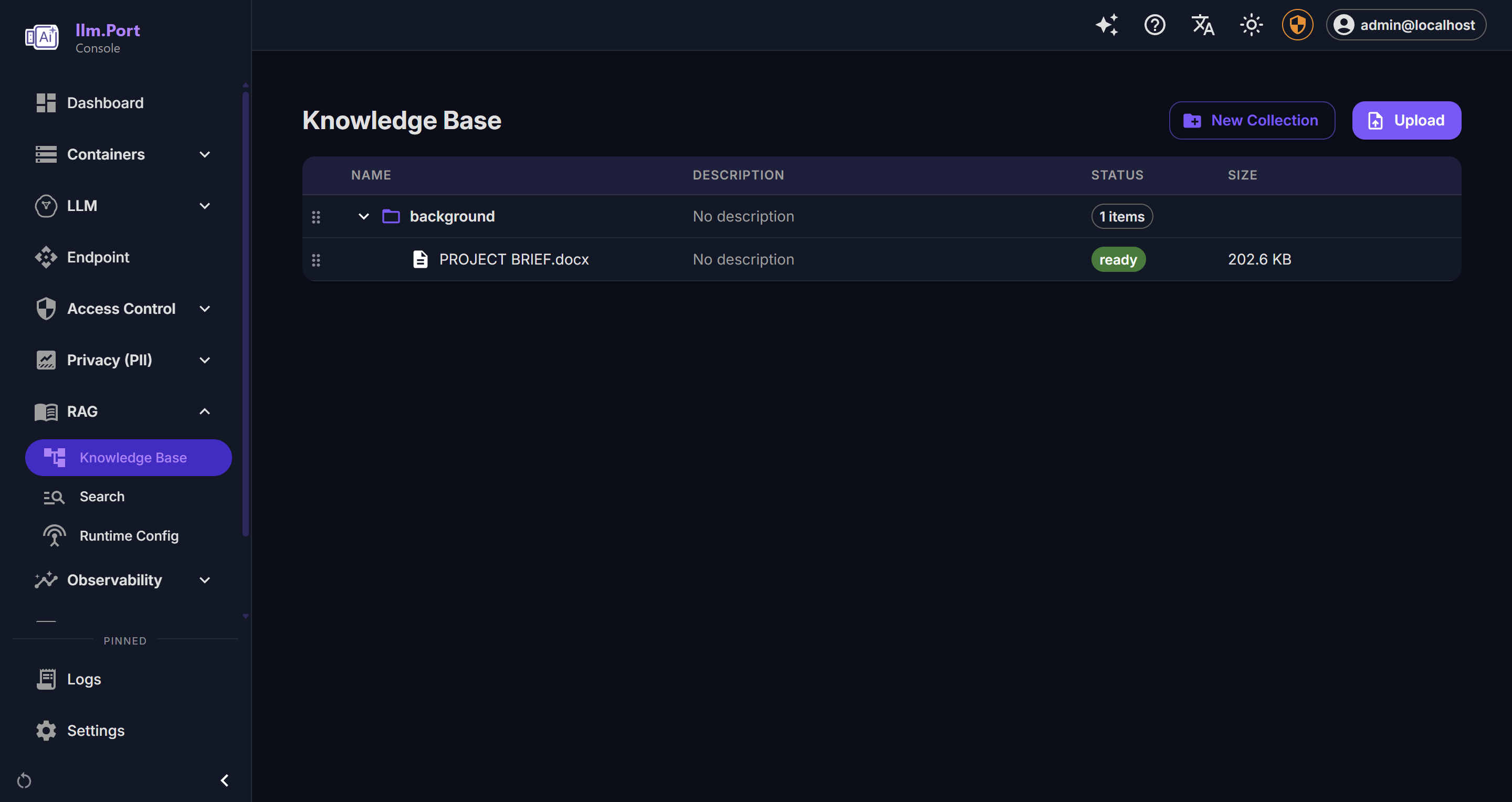 Knowledge Base
Knowledge Base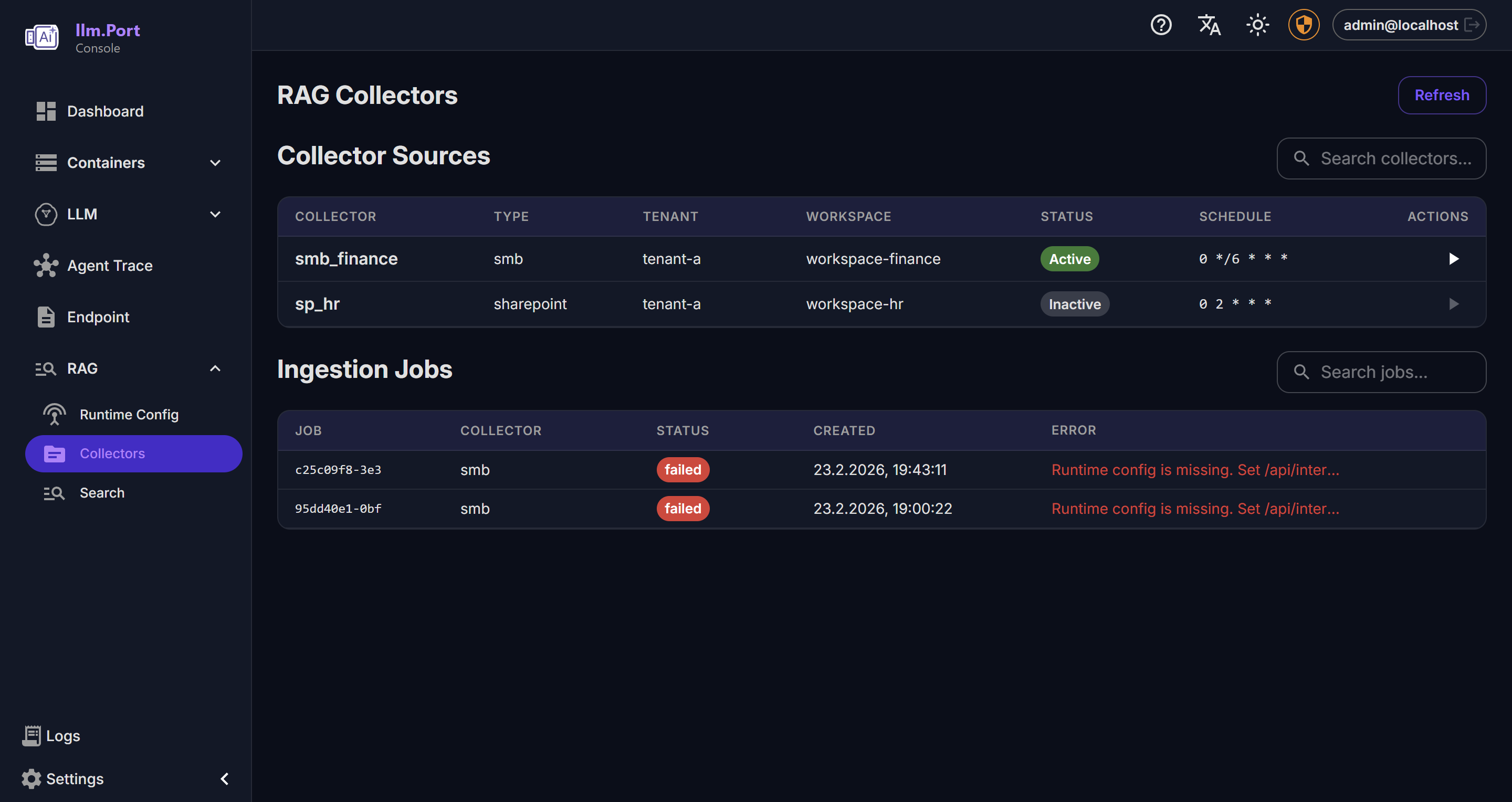 RAG Collectors
RAG Collectors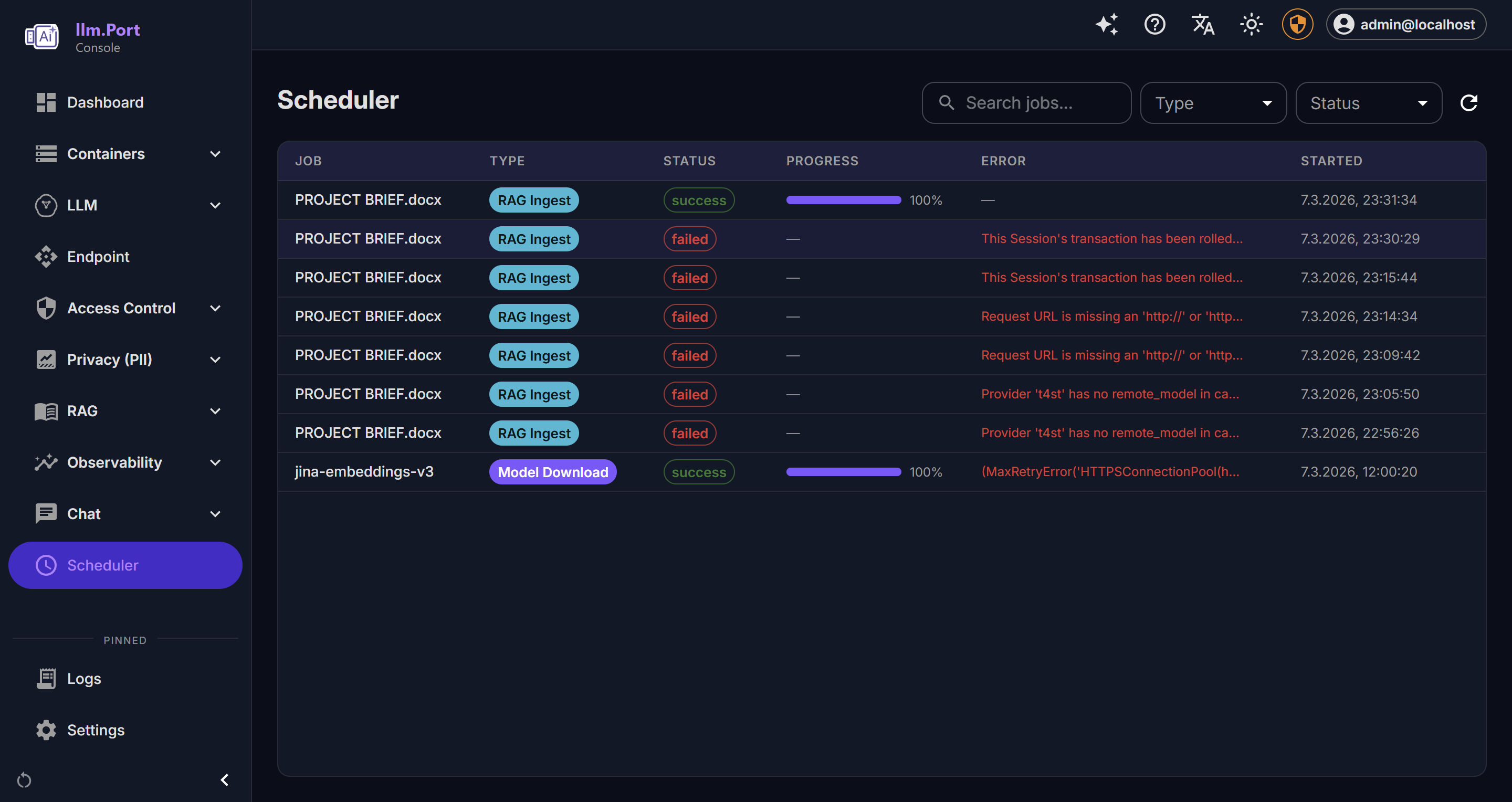 Scheduled Publishing
Scheduled Publishing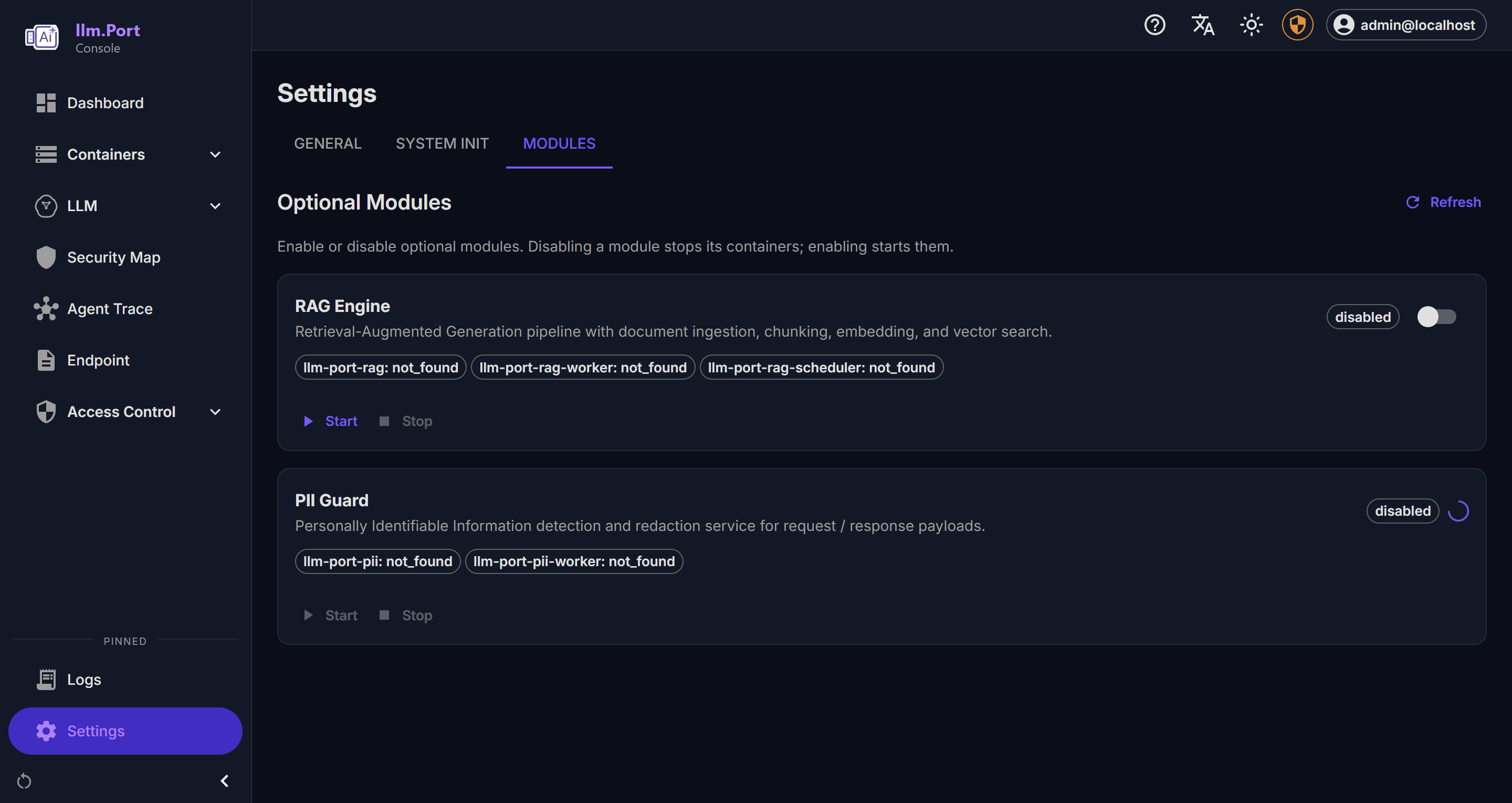 Modules
Modules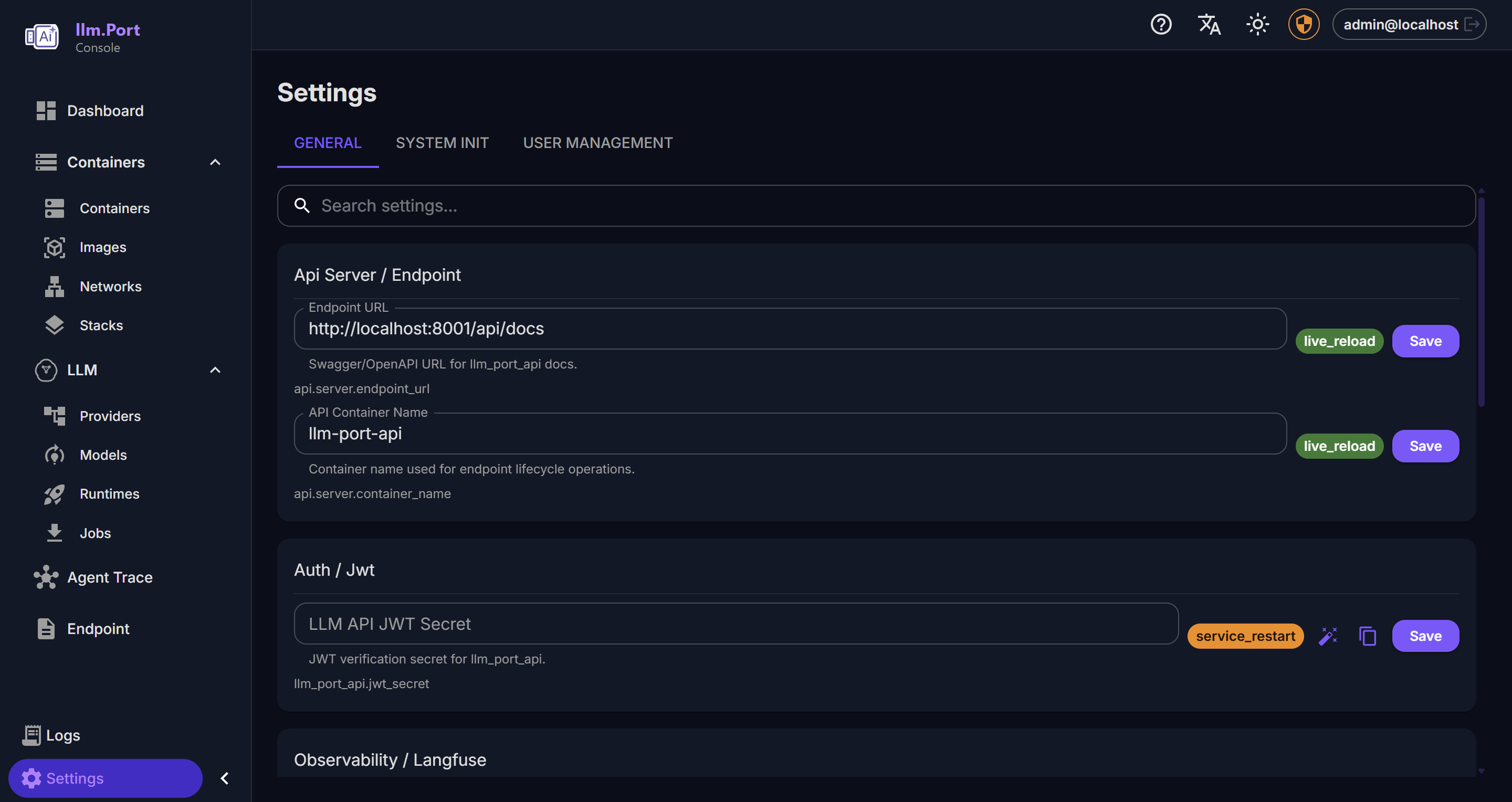 Settings
Settings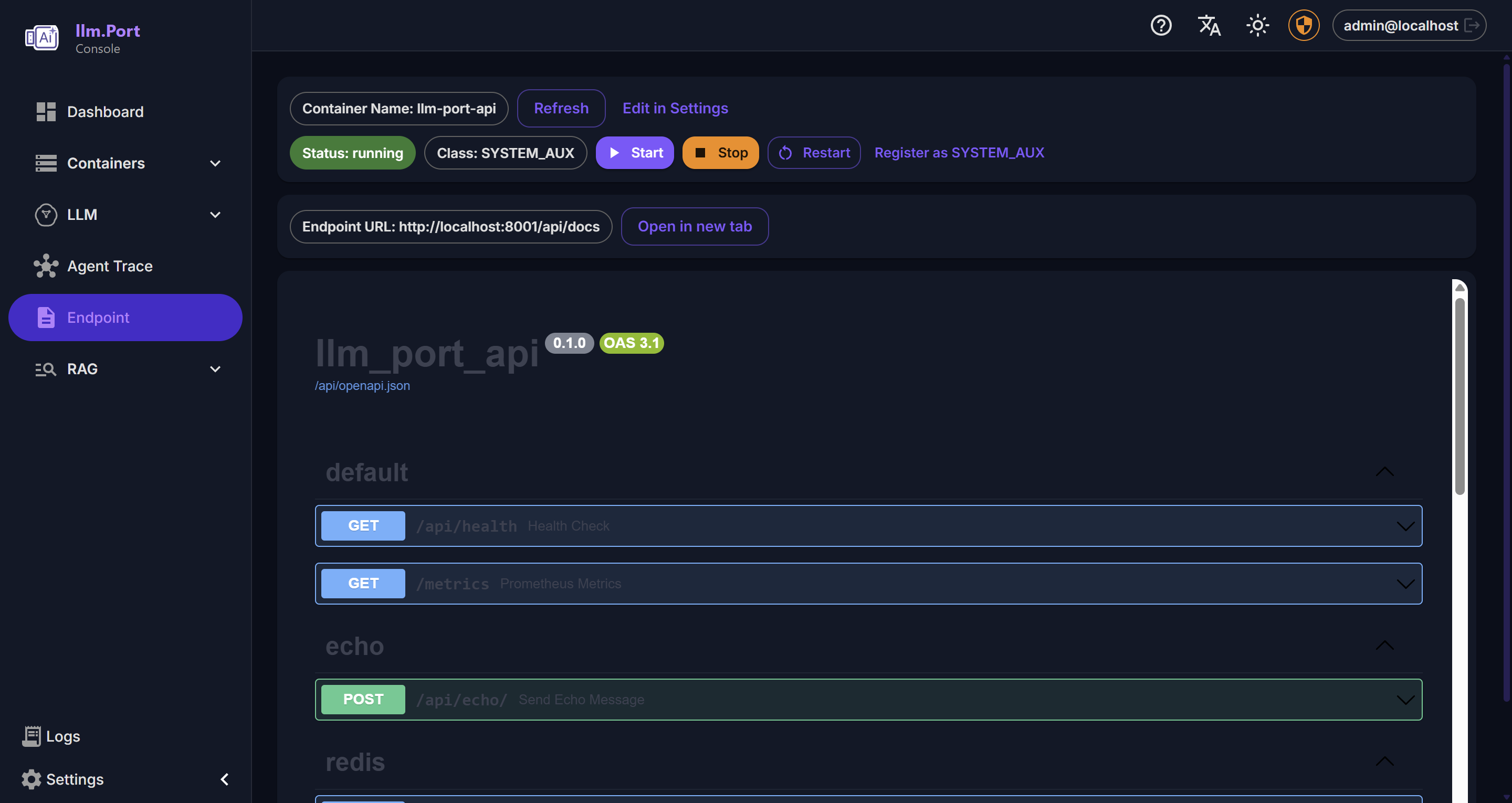 API Playground
API PlaygroundFunciones enterprise disponibles para equipos que necesitan SSO, tokenización PII avanzada y gobernanza. Contáctanos →